Linux-常用命令
前言
CTF比赛中经常遇到各种对linux命令的过滤,这个时候就要求我们掌握更多的这一类型命令的平替。这个文章进行了尽可能详尽的命令执行方面的技巧和姿势
linux对大小写敏感,windows对大小写不敏感
ls|dir|nl|nc|cat|tail|more|flag|sh|cut|awk|strings|od|curl|ping|*|sort|ch|zip|mod|sl|find|sed|cp|mv|ty|grep|fd|df|sudo|more|cc|tac|less|head|.|{|}|tar|zip|gcc|uniq|vi|vim|file|xxd|base64|date|bash|env|?|wget|'|"|id|whoami/i
命令
读文件
cat用于连接文件并显示输出到标准输出设备上。
tac从最后一行到第一行的顺序读文件。
nl为文件中的每一行加上行号。
less用于在终端中分页显示文件内容,可以向上或向下滚动并搜索内容。
strings打印文件中可打印的字符
more也是用于在终端中分页显示文件内容,与less类似,但是不能向上滚动。
head用于显示文件的前几行,默认显示文件的前10行。
tail用于显示文件的后几行,默认显示文件的后10行。
grep用于在文件中查找特定字符串并显示匹配的行。 可以用正则表达式的方式读flag
awk用于处理文本文件中的数据,可以对文件内容进行格式化、统计和转换等操作。awk '{print $1}' filename
sed用于流编辑器,可以对文件进行编辑、替换和删除等操作。sed 's/old/new/g' filename
cut用于从文件中剪切文本,并按列或字段进行输出。cut -d"," -f2 filename
paste命令将多个文件的行合并为单个输出,每个文件的一行依次排列。
sort命令按照字典顺序排序文件内容,并将其输出。
uniq命令从输入中删除重复行,并将其输出。
comm命令用于比较两个已排序的文件,并显示它们之间的差异。comm file1 file2
comm -3 文件1 文件2 打印在文件1 中有,而文件2 中没有的行。反之亦然。
diff命令用于比较两个文件之间的差异,并将其输出。
wc命令用于计算文件中的字节数、单词数和行数。
od以不同格式显示文件内容,如八进制,十进制,十六进制等,默认八进制。od -x fielname输出16进制
fold将长行折叠成短行。
hexdump以十六进制和ASCII码的形式显示文件内容。
pr将文件格式化为打印格式。
rev反转文件中的每行字符顺序。
写文件
在Linux中,">“和”»“都是输出重定向符号,它们用于将命令的输出重定向到文件或者其他命令中。
“>“表示覆盖写入,如果输出重定向的文件已经存在,会将原有内容清空,然后将新的输出写入到文件中。
“»“表示追加写入,如果输出重定向的文件已经存在,会将新的输出追加到文件末尾,而不会清空原有内容。
- echo:将字符串或变量写入标准输出或文件中。 例如: echo “Hello, world!” > hello.txt
- cat:将文件内容写入标准输出或文件中。 例如: cat file1.txt > file2.txt
- touch:创建一个空文件或更改现有文件的访问和修改时间戳。 例如: touch newfile.txt
- printf:将格式化的字符串写入标准输出或文件中。 例如: printf “The answer is %d\n” 42 > answer.txt
- tee:从标准输入读取数据并将其写入标准输出和一个或多个文件中。 例如: ls -l | tee filelist.txt
- dd:以指定的块大小从一个文件复制到另一个文件。 例如: dd if=inputfile of=outputfile bs=1M count=10
- cp:将一个或多个文件复制到目标目录或文件中。 例如: cp file1.txt file2.txt destination_folder/
- mv:移动一个或多个文件到目标目录或文件中,也可以用来更改文件名。 例如: mv file1.txt file2.txt destination_folder/
- nano:一个基本的文本编辑器,可以用来创建和编辑文本文件。 例如: nano newfile.txt
- vi:另一个文本编辑器,通常比nano更强大,但也更复杂。 例如: vi newfile.txt
- ed:一个类似vi的文本编辑器,但命令行更为简洁。 例如: ed newfile.txt
- sed:一个流编辑器,用于对文件中的文本进行替换、删除、添加等操作。 例如: sed ’s/oldtext/newtext/g’ file.txt > newfile.txt
- awk:一个强大的文本处理工具,可以用于过滤和处理文本文件。 例如: awk ‘{print $1}’ file.txt > newfile.txt
- tee:将标准输入写入一个或多个文件,并同时将其发送到标准输出。 例如: ls -l | tee filelist.txt
- echo -e:可以使用转义字符来格式化字符串并将其写入文件。 例如: echo -e “The answer is:\n42” > answer.txt
找文件
find. -name “fla*”
locatefla* 这个命令无需指定路径直接搜索即可,他是在一个每天更新的数据库mlocate.db中查找的
while查找可执行文件的位置
whereis在系统默认安装目录查找二进制文件、源码、文档中给定查询关键词的文件
找内容
grep -ar fla* /递归的找根目录
grep 'fla*' *不递归找当前目录
-a参数表示将二进制文件视为文本文件进行搜索。-r参数表示递归地在目录及其子目录中搜索文件。
读目录
dir在Windows和DOS操作系统中,dir命令可以显示当前目录中的文件和子目录列表。
ls读目录
llls的升级版
la类似ls
l类似ls
vdir类似ll
tree:tree命令可以显示当前目录及其子目录的树形结构,可以方便地查看目录结构。
lsof:lsof命令可以列出当前系统上所有打开的文件和网络连接,可以查看进程所打开的文件和网络连接情况。
lsattr:lsattr命令可以列出当前目录中所有文件和目录的扩展属性,可以查看文件和目录的扩展属性情况。
查看当前可用命令
compgen -c
管道符
使用管道符可以将多个命令连接在一起,形成一个复杂的命令序列。例如,下面的命令将“ls”命令的输出通过管道符传递给“grep”命令,然后再将“grep”命令的输出通过管道符传递给“wc”命令,以计算包含“test”的文件数目:
ls | grep test | wc -l需要注意的是,管道符连接的两个命令必须是可以通过标准输入输出进行通信的命令。此外,管道符连接的命令序列中,每个命令都是独立的,不会影响其他命令的执行。
xargs
xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。
之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了 xargs 命令,例如:
find /sbin -perm +700 |ls -l #这个命令是错误的
find /sbin -perm +700 |xargs ls -l #这样才是正确的xargs 一般是和管道一起使用。
命令格式:
somecommand |xargs -item command参数:
- -a file 从文件中读入作为 stdin
- -e flag ,注意有的时候可能会是-E,flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
- -p 当每次执行一个argument的时候询问一次用户。
- -n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
- -t 表示先打印命令,然后再执行。
- -i 或者是-I,这得看linux支持了,将xargs的每项名称,一般是一行一行赋值给 {},可以用 {} 代替。
- -r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。
- -s num 命令行的最大字符数,指的是 xargs 后面那个命令的最大命令行字符数。
- -L num 从标准输入一次读取 num 行送给 command 命令。
- -l 同 -L。
- -d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符。
- -x exit的意思,主要是配合-s使用。。
- -P 修改最大的进程数,默认是1,为0时候为as many as it can ,这个例子我没有想到,应该平时都用不到的吧。
软&硬连接
https://www.jianshu.com/p/b035d94fa959
- **链接:**一种在共享文件和访问它的用户的若干目录项之间建立联系的一种方法。
- **【硬链接】(hard link):**指通过索引节点来进行连接,就是一个文件(不是文件夹)的别名,无论有多少各别名,但它其实是一个文件。 可以这样理解:
一面墙上有一个洞,洞里放着一个苹果。从墙的这一面看是这个苹果,从墙的另一面看还是同一个苹果 也就是说同一块数据但有两个不同的名字,读写的时候本质上都是修改的同一块数据。
硬链接的删除:
硬链接在删除的时候只是删除了一个名字,只有一块数据的所有名字都删除了的时候,数据才会被删除。(删除的时候相当于把墙的这一面糊上,但苹果本身不动,只有两面都糊上了,你才会看不到)
- 【软链接】(又称符号链接,即 soft link 或 symbolic link):相当于我们 Windows 中的快捷方式,即如果你软链接一个目录,只是一个目录的快捷方式到指定位置,操作系统找这个快捷方式会直接找到真实目录下的文件。 可以这样理解:
我声称我有一个苹果,但是当你找我要的时候,我对你说,到某个建筑物的仓库就可以拿到那个苹果了。可见我并不真正拥有一个苹果,我只是拥有“某个地方有一个苹果”这个信息。但对于外部的观察者来说,这跟我实际上拥有一个苹果并无差异。
软链接的删除:
假设我死了,不会影响到原始数据。假设原始数据没了,那我这个符号链接就变成了一张空头支票,也就是悬空的符号链接。
一个符号链接可以指向一个不存在的目标,而硬链接就表示肯定有文件存在。 硬链接可以指向文件,也可以指向目录。可以跨越任何文件系统。拷贝删除原始文件或者链接文件,不会造成相互影响。
软链接:
- 1.软链接,以路径的形式存在。类似于Windows操作系统中的==快捷方式==
- 2.软链接可以==跨文件系统== ,硬链接不可以
- 3.软链接可以对一个==不存在==的文件名进行链接
- 4.软链接可以对==目录==进行链接
硬链接:
- 1.硬链接,以==文件副本==的形式存在。但不占用实际空间。
- 2.不允许给目录创建硬链接
- 3.硬链接只有在同一个文件系统中才能创建
语法
ln [参数][源文件或目录][目标文件或目录]
ln -s [源文件或目录] [目标文件或目录]
-f : 链结时先将与 dist 同档名的档案删除
-d : 允许系统管理者硬链结自己的目录
-i : 在删除与 dist 同档名的档案时先进行询问
-n : 在进行软连结时,将 dist 视为一般的档案
-s : 进行软链结(symbolic link)
-v : 在连结之前显示其档名
-b : 将在链结时会被覆写或删除的档案进行备份
-S SUFFIX : 将备份的档案都加上 SUFFIX 的字尾
-V METHOD : 指定备份的方式
--help : 显示辅助说明
--version : 显示版本多命令执行符
多命令执行符 格式 作用
; 命令1;命令2 不错的命令都会执行
&& 命令1&&命令2 逻辑与:当命令1正确执行后,命令2才会正确执行,否则命令2不会执行
|| 命令1||命令2 逻辑或:当命令1不正确执行后,命令2才会正确执行,否则命令2不会执行
windows:
| 前后两个都执行
|| 执行前面的,前面的错误就执行后面的
&& 前面的执行完执行后面的
通配符
*:匹配任意字符
ls test*
?:匹配任意单个字符
ls test?
[]:匹配括号内的任意单个字符
ls test[123]
[!]:匹配除括号内字符以外的单个字符
ls test[!123]
[^]:同[!]
通配符执行命令
可以使用通配符匹配当前目录的文件名,注意是文件名
如图
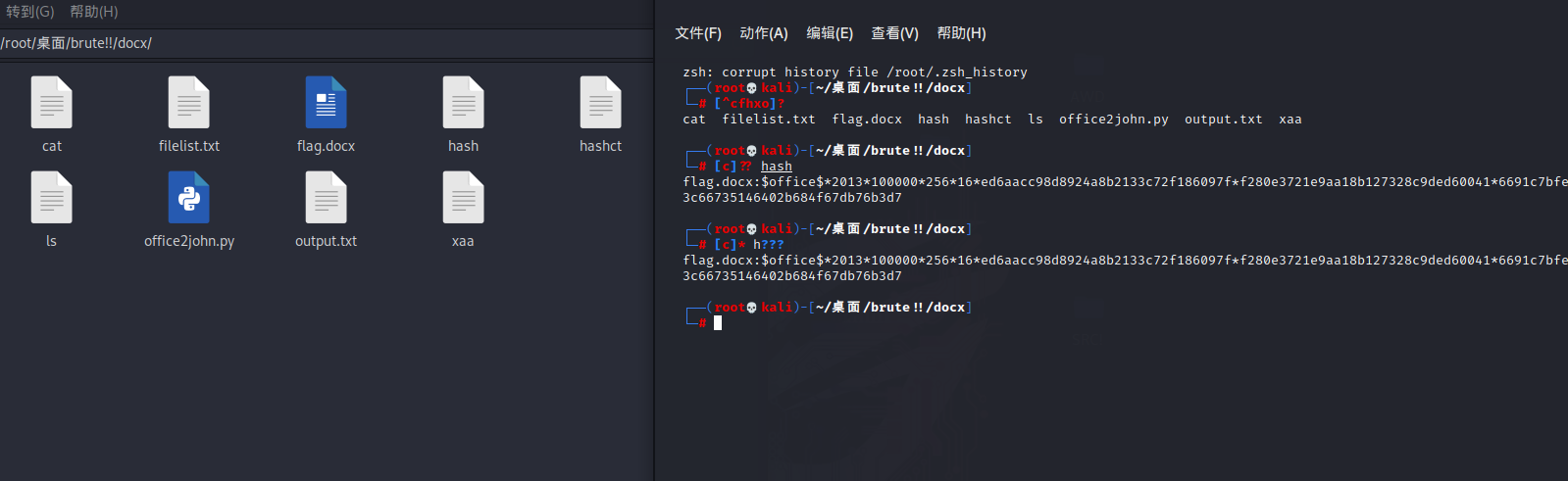
常见参数
-h:显示帮助信息-v:显示详细输出-f:指定文件名或文件列表-i:交互式操作-l:显示长列表-a:显示所有文件,包括隐藏文件-r:递归地处理文件夹中的文件-n:指定行数-q:安静模式,不输出任何信息
其他常用命令
==grep==
1.在文件中搜索模式要在文件中搜索模式,请使用以下命令:
grep “pattern” filename
其中,“pattern"是要搜索的模式,而filename是要搜索的文件的名称。例如,要在file.txt文件中搜索单词"hello”,可以使用以下命令:
grep “hello” file.txt
2.搜索多个文件要在多个文件中搜索模式,请使用以下命令:
grep “pattern” file1 file2 file3
其中,file1、file2和file3是要搜索的文件的名称。例如,要在file1.txt、file2.txt和file3.txt文件中搜索单词"hello”,可以使用以下命令:
grep “hello” file1.txt file2.txt file3.txt
3.搜索文件夹中的所有文件要搜索文件夹中的所有文件,请使用以下命令:
grep “pattern” folder/*
其中,“pattern"是要搜索的模式,而folder是要搜索的文件夹的名称。例如,要在folder文件夹中搜索所有包含单词"hello"的文件,可以使用以下命令:
grep “hello” folder/*
4.使用正则表达式搜索模式要使用正则表达式搜索模式,请使用以下命令:
grep “regex” filename
其中,“regex"是要搜索的正则表达式,而filename是要搜索的文件的名称。例如,要在file.txt文件中搜索所有以单词"hello"开头的行,可以使用以下命令:
grep “^hello” file.txt
这些是grep命令的一些基本用法。使用man grep命令可以查看更多关于grep命令的详细信息和选项。
==mv==
除了移动文件,当移动前后是同一个目录还可以重命名
mv [option] [source] [destination]
[option]
-i:在移动或重命名文件时,如果目标文件已经存在,则提示用户确认是否覆盖目标文件。-f:强制移动或重命名文件或目录,如果目标文件已经存在,则覆盖它而不提示用户确认。-n:不要覆盖目标文件或目录,如果文件或目录已经存在,则不移动或重命名它。-v:显示详细输出,给出操作的进度和结果。-u:只会在源文件比目标文件新或者目标文件不存在的情况下才会执行移动或重命名操作,否则不执行。
==cp==
作用是复制文件或目录
cp [option] [source] [destination]
[option]
-i:在复制文件或目录时,如果目标文件已经存在,则提示用户确认是否覆盖目标文件。-f:强制复制文件或目录,如果目标文件已经存在,则覆盖它而不提示用户确认。-n:不要覆盖目标文件或目录,如果文件或目录已经存在,则不复制它。-r:复制目录及其所有内容。-v:显示详细输出,给出操作的进度和结果。
==tar==
创建和管理 tar 归档文件
tar [option] [archive-name] [file or directory to be archived]
option是一些可选参数,archive-name是要创建的 tar 归档文件的名称,file or directory to be archived是要包含在归档文件中的文件或目录的路径。[option]
-c:创建归档文件。-t:查看归档文件中的内容。-x:从归档文件中提取内容。-v:显示详细输出,给出操作的进度和结果。-f:指定要操作的归档文件的名称。
==zip==
创建和管理 ZIP 压缩文件
zip [option] [archive-name] [file or directory to be compressed]
[option]
-r:递归地压缩目录和它们的子目录。-q:不显示命令输出。-v:显示详细输出,给出操作的进度和结果。-f:指定要操作的 ZIP 文件的名称。-y:不提示用户的情况下将所有文件包含在 ZIP 压缩文件中
压缩算法:`tar` 使用的是无损压缩算法(例如 gzip 或 bzip2),而 `zip` 使用的是有损压缩算法(例如 Deflate)。
文件格式:`tar` 创建的是一个归档文件,而 `zip` 创建的是一个压缩文件。
- 归档文件:归档文件只是将多个文件和目录打包到一个文件中,不进行压缩。归档文件通常用于备份或迁移文件,因为它们可以保留文件属性和权限等元数据。
- 压缩文件:压缩文件是将文件压缩到一个更小的文件中,以节省存储空间和传输时间。==sed==
用于对文本文件进行替换、删除、插入、追加等操作
sed [option] ‘command’ file
option是一些可选参数,command是要执行的 sed 命令,file是要处理的文件名或标准输入流
-i:直接修改原始文件,而不是输出到标准输出流。-e:允许多个命令在同一行上执行。-n:禁止输出,只有经过指定处理的行才会输出。
==string==
用于在二进制文件中查找 ASCII 和 Unicode 字符串
string [option] [file(s)]
[option]
-a:输出所有字符串,包括打印出来的字符串。-n length:设置输出的字符串的最小长度。-t format:设置输出的字符串的格式。可选的格式包括 ASCII、little-endian Unicode、big-endian Unicode 和 both-endian Unicode。-e:仅输出找到的字符串的偏移量和长度,而不输出字符串本身。
==expr==
可以用来进行数值运算和字符串操作
查找字符串匹配到的位置
$ expr index "Hello World" "Wo"
7
$ expr "Hello World" : "Hello"
5数值运算
$ expr 5 + 3
8
$ expr 10 - 4
6
$ expr 4 \* 3
12
$ expr 20 / 5
4