SQL进阶操作
数据类型
| CHARACTER(n) | 字符/字符串。固定长度 n。 |
|---|---|
| VARCHAR(n) 或 CHARACTER VARYING(n) | 字符/字符串。可变长度。最大长度 n。 |
| BINARY(n) | 二进制串。固定长度 n。 |
| BOOLEAN | 存储 TRUE 或 FALSE 值 |
| VARBINARY(n) 或 BINARY VARYING(n) | 二进制串。可变长度。最大长度 n。 |
| INTEGER(p) | 整数值(没有小数点)。精度 p。 |
| SMALLINT | 整数值(没有小数点)。精度 5。 |
| INTEGER | 整数值(没有小数点)。精度 10。 |
| BIGINT | 整数值(没有小数点)。精度 19。 |
| DECIMAL(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数,小数点后有 2 位数的数字。 |
| NUMERIC(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| FLOAT(p) | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| REAL | 近似数值,尾数精度 7。 |
| FLOAT | 近似数值,尾数精度 16。 |
| DOUBLE PRECISION | 近似数值,尾数精度 16。 |
| DATE | 存储年、月、日的值。 |
| TIME | 存储小时、分、秒的值。 |
| TIMESTAMP | 存储年、月、日、小时、分、秒的值。 |
| INTERVAL | 由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| ARRAY | 元素的固定长度的有序集合 |
| MULTISET | 元素的可变长度的无序集合 |
| XML | 存储 XML 数据 |
关键字
INDEX
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
用户无法看到索引,它们只能被用来加速搜索/查询。
**注释:**更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
SQL CREATE INDEX 语法
在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column_name)SQL CREATE UNIQUE INDEX 语法
在表上创建一个唯一的索引。不允许使用重复的值:唯一的索引意味着两个行不能拥有相同的索引值。Creates a unique index on a table. Duplicate values are not allowed:
CREATE UNIQUE INDEX index_name
ON table_name (column_name)**注释:**用于创建索引的语法在不同的数据库中不一样。因此,检查您的数据库中创建索引的语法。
CREATE INDEX 实例
下面的 SQL 语句在 “Persons” 表的 “LastName” 列上创建一个名为 “PIndex” 的索引:
CREATE INDEX PIndex
ON Persons (LastName)如果您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:
CREATE INDEX PIndex
ON Persons (LastName, FirstName)DISTINCT
在表中,一个列可能会包含多个重复值,有时您也许希望仅仅列出不同(distinct)的值。
DISTINCT 关键词用于返回唯一不同的值。
SELECT DISTINCT column1, column2, ...
FROM table_name;ORDER BY
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 DESC 关键字。
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;- column1, column2, …:要排序的字段名称,可以为多个字段。
- ASC:表示按升序排序。
- DESC:表示按降序排序。
演示
SELECT * FROM Websites
ORDER BY country,alexa;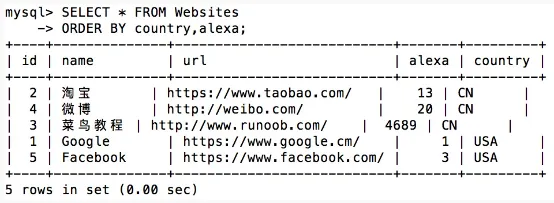
INSERT INTO
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);UPDATE
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;DELETE
DELETE FROM table_name
WHERE condition;TOP
SELECT TOP 子句用于规定要返回的记录的数目
SQL Server / MS Access 语法
SELECT TOP number|percent column_name(s)
FROM table_name;MySQL 语法
SELECT column_name(s)
FROM table_name
LIMIT number;Oracle 语法
SELECT column_name(s)
FROM table_name
WHERE ROWNUM <= number;LIKE
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
平替:REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE)
SELECT column1, column2, ...
FROM table_name
WHERE column LIKE pattern;在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist] 或 [!charlist] | 不在字符列中的任何单一字符 |
IN
IN 操作符允许您在 WHERE 子句中规定多个值。
SELECT column1, column2, ...
FROM table_name
WHERE column IN (value1, value2, ...);BETWEEN
BETWEEN 操作符用于选取介于两个值之间的数据范围内的值。
SELECT column1, column2, ...
FROM table_name
WHERE column BETWEEN value1 AND value2;示例
SELECT * FROM Websites
WHERE (alexa BETWEEN 1 AND 20)
AND country NOT IN ('USA', 'IND');
下面的 SQL 语句选取 name 以介于 'A' 和 'H' 之间字母开始的所有网站:
SELECT * FROM Websites
WHERE name BETWEEN 'A' AND 'H';
下面的 SQL 语句选取 name 不介于 'A' 和 'H' 之间字母开始的所有网站:
SELECT * FROM Websites
WHERE name NOT BETWEEN 'A' AND 'H';GROUP BY
GROUP BY 语句用于结合==聚合函数==,根据一个或多个列对结果集进行分组
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;示例
下面是选自 “Websites” 表的数据:
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+下面是 “access_log” 网站访问记录表的数据:
mysql> SELECT * FROM access_log;
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
9 rows in set (0.00 sec)单表
SELECT site_id, SUM(access_log.count) AS nums
FROM access_log GROUP BY site_id;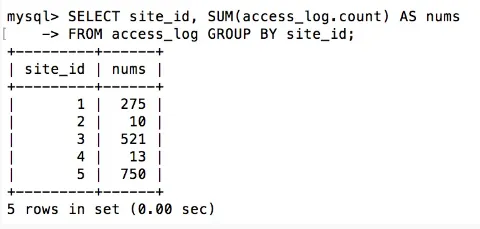
多表
SELECT Websites.name,COUNT(access_log.aid) AS nums FROM access_log
LEFT JOIN Websites
ON access_log.site_id=Websites.id
GROUP BY Websites.name;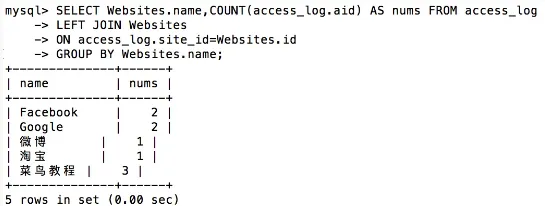
HAVING
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1
HAVING condition;示例
SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_log
INNER JOIN Websites
ON access_log.site_id=Websites.id)
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;别名
通过使用 SQL,可以为表名称或列名称指定别名。
基本上,创建别名是为了让列名称的可读性更强。
列的 SQL 别名语法
SELECT column_name AS alias_name
FROM table_name;表的 SQL 别名语法
SELECT column_name(s)
FROM table_name AS alias_name;示例
SELECT name, CONCAT(url, ', ', alexa, ', ', country) AS
site_info
FROM Websites;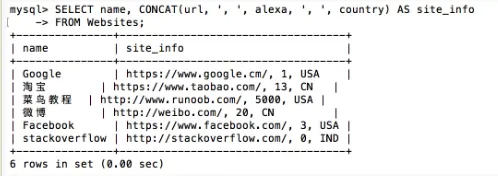
不带别名
SELECT Websites.name, Websites.url, access_log.count, access_log.date FROM
Websites, access_log
WHERE Websites.id=access_log.site_id and Websites.name="菜鸟教程";
带别名
SELECT w.name, w.url, a.count, a.date FROM
Websites AS w, access_log AS a
WHERE a.site_id=w.id and w.name="菜鸟教程";JOIN
SQL join 用于把来自两个或多个表的行结合起来。
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)。 SQL INNER JOIN 从多个表中返回满足 JOIN 条件的所有行。
SELECT column1, column2, ...
FROM table1
JOIN table2 ON condition;示例
SELECT Websites.id, Websites.name, access_log.count, access_log.dateFROM
WebsitesINNER JOIN access_logON Websites.id=access_log.site_id;SELECT INTO
SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中。
我们可以复制所有的列插入到新表中:
SELECT *
INTO newtable [IN externaldb]
FROM table1;或者只复制希望的列插入到新表中:
SELECT column_name(s)
INTO newtable [IN externaldb]
FROM table1;AUTO_INCREMENT
Auto-increment 会在新记录插入表中时生成一个唯一的数字。
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)EXISTS
EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);示例
显示所有已经选修了课程的学生信息
select * from student s where exists (select * from sc where s.sno=sc);函数
SQL Aggregate 函数
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
- AVG() - 返回平均值
- COUNT() - 返回行数
- FIRST() - 返回第一个记录的值
- LAST() - 返回最后一个记录的值
- MAX() - 返回最大值
- MIN() - 返回最小值
- SUM() - 返回总和
SQL Scalar 函数
SQL Scalar 函数基于输入值,返回一个单一的值。
有用的 Scalar 函数:
- UCASE() - 将某个字段转换为大写
- LCASE() - 将某个字段转换为小写
- MID() - 从某个文本字段提取字符,MySql 中使用
- SubString(字段,1,end) - 从某个文本字段提取字符
- LEN() - 返回某个文本字段的长度
- ROUND() - 对某个数值字段进行指定小数位数的四舍五入
- NOW() - 返回当前的系统日期和时间
- FORMAT() - 格式化某个字段的显示方式
视图 VIEW
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE conditionSQL SERVER
ALTER VIEW [ schema_name . ] view_name [ ( column [ ,...n ] ) ]
[ WITH <view_attribute> [ ,...n ] ]
AS select_statement
[ WITH CHECK OPTION ] [ ; ]
<view_attribute> ::=
{
[ ENCRYPTION ]
[ SCHEMABINDING ]
[ VIEW_METADATA ]
} - schema_name: 视图所属架构的名称。
- view_name: 要更改的视图。
- column: 将成为指定视图的一部分的一个或多个列的名称(以逗号分隔)。
删除视图
DROP VIEW view_name修改视图
ALTER VIEW my_view AS
SELECT column1, column2
FROM my_table
WHERE new_condition;插入数据到视图
INSERT INTO my_view (column1, column2) VALUES (value1, value2);更新视图
UPDATE my_view
SET column1 = new_value
WHERE condition;删除数据
DELETE FROM my_view
WHERE condition;查询视图
SELECT * FROM my_view;权限
GRANT
发出如下语句的可以是数据库管理员、也可以是数据库对象创建者、也可以是已经拥有该权限的用户
GRANT 权限 ON 对象类型对象名 TO 用户名 [WITH GRANT OPTION];
权限:查询权限SELECT,全部操作权限ALL PRIVILEGES
对象类型&对象名:对象类型可以是TABLE也可以是VIEW,对象名为对应的表名或者视图名
用户名:可以是指定用户,也可以是全体用户PUBLIC如果没有指定WITH GRANT OPTION子句,则获得某种权限的用户只能使用该权限,不能传播该权限
注意:SQL不允许循环授权,即被授权者不能把权限再授回给授权者或其祖先
eg.把查询权限授给用户U1
GRANT SELECT ON TABLE Student TO U1;
REVOKE
REVOKE 权限 ON 对象类型 对象名 FROM 用户名 [CASCADE|RESTRICT];
CASCADE:级联回收。将用户传播出去的权限─并收回
RESTRICT:受限回收。若用户传播过该权限,回收将会失败eg.把用户U4修改学生学号的权限收回
REVOKE UPDATE(Sno) ON TABLE Student FROM U4;
约束Constraints
https://www.jb51.net/article/248801.htm
SQL 约束用于规定表中的数据规则。
如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
在 SQL 中,我们有如下约束:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。
- DEFAULT - 规定没有给列赋值时的默认值。
关键字
CONSTRAINT
-
创建表时定义约束:
CREATE TABLE 表名 ( 列名 数据类型 CONSTRAINT 约束名 约束规则, ... ); 在上述示例中,您可以在列定义之后使用CONSTRAINT来为该列定义一个约束。约束规则可以是主键约束、唯一约束、外键约束、检查约束等。 -
在已存在的表上添加约束:
ALTER TABLE 表名 ADD CONSTRAINT 约束名 约束规则; 使用ALTER TABLE语句,您可以在已存在的表上添加新的约束。约束规则的类型可以是上述列出的任何一种。 -
修改或删除约束:
ALTER TABLE 表名 DROP CONSTRAINT 约束名; 使用ALTER TABLE语句,您可以修改或删除已存在的约束。通过指定约束名,您可以删除特定的约束。
ALTER
ALTER是SQL语句中用于修改数据库对象(如表、列、约束等)的关键字
-
ALTER TABLE(修改表):
-
添加列:
ALTER TABLE 表名 ADD 列名 数据类型; -
修改列的数据类型:
ALTER TABLE 表名 ALTER COLUMN 列名 TYPE 新数据类型; -
修改列名:
ALTER TABLE 表名 RENAME COLUMN 旧列名 TO 新列名; -
删除列:
ALTER TABLE 表名 DROP COLUMN 列名;
-
-
ALTER CONSTRAINT(修改约束):
-
修改约束名:
ALTER TABLE 表名 RENAME CONSTRAINT 旧约束名 TO 新约束名; -
禁用约束:
ALTER TABLE 表名 DISABLE CONSTRAINT 约束名; -
启用约束:
ALTER TABLE 表名 ENABLE CONSTRAINT 约束名;
-
-
ALTER INDEX(修改索引):
-
重命名索引:
ALTER INDEX 旧索引名 RENAME TO 新索引名; -
重建索引:
ALTER INDEX 索引名 REBUILD;
-
一、分类
在SQL Server中,有3种不同类型的约束。
- 实体约束 实体约束是关于行的,比如某一行出现的值就不允许出现在其他行,例如==主键==。
- 域约束 域约束是关于列的,对于所有行,某一列有那些约束,例如CHECK约束。
- 参照完整性约束 如果某列的值必须与其他列的值匹配,那就意味着需要一个参照完整性约束,例如外键。
二、约束命名
在学习约束之前,首先来了解下为约束命名需要注意哪些地方。
SQL Server在我们不提供名称时,会自动创建名称,但是由系统自动创建的名称并不是特别有用。
例如,系统生成的主键名称可能是这样的:PK_Employees_145C0A3F。
PK代表主键(primary key),Employees代表在Employees表中,而剩下的“145C0A3F”部分是为了保证唯一性而随机生成的值。只有通过脚本创建才会得到这种值,如果是通过Managerment Studio创建表,那么就直接是PK_Employees。
对于系统自动生成的Check约束名称如:CK_Customers_22AA2996。CK代表这是一个Check约束,Customers代表是在Customers表中,后面的22AA2996还是一个随机数。如果一个表中有多个Check约束,则命名可能如下:
CK_Customers_22AA2996
CK_Customers_25869641
CK_Customers_267ABA7A
如果你需要修改这些约束其中的一个,那么你很难分辨这些约束到底是哪一个。
因此,为了能够一眼看上去就知道这个约束是用来干什么的,我们应该使用一种简单明了的短语来进行命名。
例如要确保某一列电话号码格式正确的约束,我们可以使用命名CK_Customers_PhoneNo这样的短语来命名。
总之命名要做到以下几点:
- 一致性
- 通俗易懂
- 满足以上两个条件的情况下简化名称。
三、主键约束
主键是每行的唯一标识符,仅仅通过它就能准确定位到一行,其中主键列在整个表中不能有重复,必须包含唯一的值(不能为NULL)。由于主键在关系数据库中的重要性,因此它是所有键和约束中最重要的。
下面来说说主键的创建方式
1、在创建表的时候创建主键约束。
create table customer
(
customerId int identity not null primary key,--创建主键约束
CustomerName nvarchar(30) not null
);CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (Id_P) //PRIMARY KEY约束
)2、在已存在的表上创建主键约束
现在假设已经存在了一张表,但是还没有主键约束:
alter table person
add constraint PK_Employee_Id --外键名称
primary key(personId) --personId 字段名alter名称告诉SQL Server如下信息:
- 添加了一些内容到表中(也可以删除表中的某些内容)
- 添加了什么内容(一个约束)
- 对约束的命名(允许以后直接访问约束)
- 约束的类型(主键约束)
- 约束应用于哪个列。
ALTER是用于修改数据库表的关键字。它允许你对现有表进行结构上的更改,包括添加、修改或删除列,修改表的约束条件,以及修改表的其他属性。
3、复合主键的创建
复合主键(Composite Primary Key)是指由多个列组成的主键,用于唯一标识数据库表中的每一行数据。与单一主键不同,复合主键由两个或多个列的组合形成,并且每个列的值都必须唯一。
创建表的时候
CREATE TABLE 表名 (
列1 数据类型,
列2 数据类型,
列3 数据类型,
PRIMARY KEY (列1, 列2)
);如果实在Management Studio中,创建复合主键,只需要按住Ctrl键,选中两个列,然后设置为主键就OK了,非常简单。下面主要讲述使用T-SQL创建复合主键的方法:
ALTER TABLE 表名 WITH NOCHECK
ADD CONSTRAINT [PK_表名]
PRIMARY KEY NONCLUSTERED ( [字段名1], [字段名2] )
ALTER TABLE users
ADD CONSTRAINT pk_users PRIMARY KEY (id, username);在 SQL Server 中,NONCLUSTERED 是用于创建非聚集索引的关键字。
在多对多联系中,常常会有一张表来描述其他两张表的关系,就以此读者和书为例子:
ALTER TABLE ReaderAndBook
ADD CONSTRAINT [PK_ReaderAndBook]
PRIMARY KEY NONCLUSTERED ( ReaderId, BookId )四、外键约束
一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
FOREIGN KEY 约束用于预防破坏表之间连接的行为。
FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
外键既能确保数据完整性,也能表现表之间的关系。添加了外键之后,插入引用表的记录要么必须被引用表中被引用列的某条记录匹配,要么外键列的值必须设置为NULL。
外键和主键不一样,每个表中的外键数目不限制唯一性。在每个表中,每一有-~253个外键。唯一的限制是一个列只能引用一个外键。一个列可以被多个外键引用。
4.1、创建表的时候创建外键
create table orders
(
orderId int identity not null primary key,
customerId int not null foreign key references customer(customerId)--约束类型-外键-引用表(列名)
);4.2、在已存在的表中添加一个外键
假设上面的代码去掉了添加外键行,那么可以书写代码如下:
alter table orders
add constraint FK_Orders_CustomerId --添加约束 名称
foreign key (customerId) references customer(customerId) --外键约束,外键列名,被引用列名刚添加的约束和之前添加的约束一样生效,如果某行引用customerId不存在,那么就不允许把该行添加到Orders表中。
4.3、级联动作
外键和其他类型键的一个重要区别是:外键是双向的,即不仅是限制子表的值必须存在于父表中,还在每次对父表操作后检查子行(这样避免了孤行)。SQL Server的默认行为是在子行存在时“限制”父行被删除。然而,有时会自动删除任何依赖的记录,而不是防止删除被引用的记录。同样在更新记录时,可能希望依赖的记录自动引用刚刚更新的记录。比较少见的情况是,你可能希望将引用行改变为某个已知的状态。为此,可以选择将依赖行的值设置为NULL或者那个列的默认值。
这种进行自动删除和自动更新的过程称为级联。这种过程,特别是删除过程,可以经过几层的依赖关系(一条记录依赖于另一条记录,而这另一条记录又依赖其他记录)。
在SQL Server中实现级联动作需要做的就是修改外键语法-只需要在添加前面加上ON子句。例如:
alter table orders
add constraint FK_Orders_CustomerId --添加约束 名称
foreign key (customerId) references customer(customerId) --外键约束,外键列名,被引用列名
on update no action --默认修改时不级联更新子表
on delete cascade --删除时级联删除依赖行当在进行级联删除时,如果一个表级联了另一个表,而另一个表又级联了其他表,这种级联会一直下去,不受限制,这其实是级联的一个危险之处,很容易一个不小心删掉大量数据。
级联动作除了no action,cascade之外,还有set null和set default。后两个是在SQL Server2005中引入的,如果要兼容到SQL Server2000的话,要避免使用这两个级联动作。但是他们的才做是非常简单的:如果执行更新而改变了一个父行的值,那么子行的值将被设置为NULL,或者设置为该列的默认值(不管SET NULL还是SET DEFAULT)。
五、唯一约束
唯一约束与主键比较相似,共同点在于它们都要求表中指定的列(或者列的组合)上有一个唯一值,区别是唯一约束没有被看作表中记录的唯一标识符(即使你可以按这样的方式使用也有效),而且==可以有多个唯一约束==(而在每个表中只能有一个主键)。
一旦建立了唯一约束,那么==指定列中的每个值必须是唯一的==。如果更新或者插入一条记录在带唯一约束的列上有已经存在的值的记录,SQL Server将抛出错误,拒绝这个记录。
和主键不同,唯一约束不会自动防止设置一个NULL值,是否允许为NULL由表中相应列的NULL选项的设置决定,但即使确实允许NULL值,一张表中也只能够插入一个NULL值(如果允许多个,那就不叫唯一了)。
在已存在的表上创建唯一约束:
alter table Account
add constraint AK_AccountName --约束名
unique (Account_Name) -- 列名AK代表替换键(Alternate Key),唯一约束也叫替换键。
主键和唯一约束的区别:
- 主键约束不允许出现NULL值。任何索引的索引键都不允许包含null值。但唯一约束允许包含NULL值,但唯一约束把两个NULL值当作重复值,所以施加了唯一约束的每一列只允许包含一个NULL值。
- 创建主键时会自动创建聚集索引,除非当前表中已经含有了聚集索引或是创建主键时指定了NONCLUSTERED关键字。
- 创建唯一约束时会自动创建非聚集索引,除非你指定了CLUSTERED关键字并且当前表中还没有聚集索引。
- 每个表中只能有一个主键,但可以由多个唯一约束。
六、CHECK约束
CHECK约束约束可以和一个列关联,也可以和一个表关联,因为它们可以检查一个列的值相对于另外一个列的值,只要这些列都在同一个表中以及值是在更新或者插入的同一行中。CHECK约束还可以用于检查列值组合是否满足某一个标准。
可以像使用where子句一样的规则来定义CHECK约束。CHECK约束条件的示例如下:
- 限制Month列为合适的数字:BETWEEN 1 AND 12
- 正确的SSN格式:LIKE’[0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9]'
- 限制为一个快递公司的特定列表:IN(‘UPS’,‘Fed Ex’,EMS’)
- 价格必须为正数:UnitPrice >= 0
- 引用同一行中的另外一列:ShipDate >= OrderDate
上面给出的列表只是一小部分,而条件实际上市无限多的。几乎所有可以放到where子句的条件都可以放到该约束中。而且和其他选择(规则和触发器)相比,CHECK约束执行速度更快。
创建表的时候创建check约束
CREATE TABLE Persons
(
P_Id int NOT NULL CHECK (P_Id>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)在已存在的表中添加一个CHECK约束:
alter table Account
add constraint CN_AccountAge
check (Account_Age > 18); -- 插入年龄必须大于18如果此时视图添加一条不满足的记录,将报如下错误:
insert into Account values (22,'洪',17)
消息 547,级别 16,状态 0,第 1 行
INSERT 语句与 CHECK 约束"CN_AccountAge"冲突。该冲突发生于数据库"Nx",表"dbo.Account", column 'Account_Age'。
语句已终止。七、DEFAULT约束
和所有约束一样,DEFAULT约束也是表定义的一个组成部分,它定义了当插入的新行对于定义了默认约束的列未提供相应数据时该怎么办。可以定义它为一个字面值(例如,设置默认薪水为0,或者设置字符串列为"UNKNOWN"),或者某个系统值(getdate())。
对于DEFAULT约束,要了解以下几个特性:
1、默认值只在insert语句中使用。在update语句和delete语句中被忽略。
2、如果在insert语句中提供了任意值,那就不使用默认值。
3、如果没有提供值,那么总是使用默认值。
值得注意的是,update命令的规则有一个例外,如果显示说明使用默认值就是例外。可以通过使用关键字DEFAULT表示更新的值设置为默认值。
7.1在创建表时定义DEFAULT约束:
create table person
(
person_id int identity not null primary key,
person_name nvarchar(30) not null default '无名氏',
person_age int not null
)在执行语句后:
insert into person (person_age) values(24)表中被插入一条记录如下:
7.2在已存在的表上添加DEFAULT约束:
alter table person
add constraint CN_DefaultName
default '无名氏' for person_name八、禁用约束
有时我们想暂时或永久地消除约束。但是SQL Server并没有提供删除约束的方法。SQL Server只允许禁用外键约束或CHECK约束,而同时保持约束的完整性。
禁用一个数据完整性规则通常是因为已经有无效数据了。这样的数据通常分为以下两类:
1、在创建约束时已经在数据库中的数据
2、在约束创建以后希望添加的数据
SQL Server允许禁用完整性检查一段时间来对例外的无效数据作处理,然后再重新启用完整性(不是物理删除数据完整性约束)。
注意:不能禁用主键约束或者唯一约束
8.1、在创建约束时,忽略检查之前的不满足数据
要添加一个约束,但是有不应用到已存在的数据中,可以再执行Alter Table语句添加约束时使用WITH NOCHECK选项。
按照上面创建Check约束的方法,已经Alter Table时,表中本身已经存在不符合的数据,那么Alter Table操作将被SQL Server拒绝执行。除非已经存在的所有数据都满足CHECK约束的条件,否则SQL Server不会执行创建约束的命令。要解决这个问题,我们可以添加WITH NOCHECK。
我们先新建一个表只有3个字段的表,Id、姓名、年龄,并在里面插入一条不满足要求的数据:
insert into Account values (23,'洪',17)然后执行添加约束命令:
alter table Account
add constraint CN_AccountAge18
check (Account_Age > 18); -- 插入年龄必须大于18SQL Server报一下错误:
消息 547,级别 16,状态 0,第 1 行
ALTER TABLE 语句与 CHECK 约束"CN_AccountAge18"冲突。该冲突发生于数据库"Nx",表"dbo.Account", column 'Account_Age'。这时候我们换一种方式去执行:
alter table Account
WITH NOCHECK
add constraint CN_AccountAge18
check (Account_Age > 18); -- 插入年龄必须大于18以上代码就能够成功执行,并且只有以后添加的数据具备约束,之前添加的不符合条件的数据记录依然存在。
8.2、临时禁用已存在的约束
当我们需要从另一数据库中导入数据到表中,而表中已建立了约束的时候,可能会存在一些数据和规则不匹配。当然有一个解决方式是先删除约束,添加需要的数据,然后WITH NOCHECK再添加回去。但是这样做太麻烦了。我们不需要这么做。我们可以采用名为NOCHECK的选项来运行ALTER语句,这样就能够取消需要的约束。
先来看看上节中创建的这个约束:
alter table Account
add constraint CN_AccountAge18
check (Account_Age > 18); -- 插入年龄必须大于18要取消以上约束可以这样来:
Alter Table Account
NOCHECK
constraint CN_AccountAge18执行命令:
insert into Account values (25,'取消了约束',17)执行成功,成功添加了一行数据。
留意到又能够向表中插入格式不匹配的数据了。
这里要说明下,如何知道一个约束是否是启用还是禁用呢?sp_helpconstraint命令,当我们执行sp_helpconstraint的时候,会有一列status_enabled显示该约束的启用状态:
sp_helpconstraint Account
留意到status_enabled列为Disabled说明是禁用的意思。
当要启用约束时,只需要用将语句中的NO CHECK替换为CHECK就可以了:
Alter Table Account
CHECK
constraint CN_AccountAge18执行之后,约束又启用了:再来sp_helpconstraint看下:

留意到status_enabled列变成了Enabled。
status_enabled的两种状态如下:
Enabled:启用;
Disabled:禁用;
九、规则和默认值(已淘汰)
规则和默认值的应用要早于CHECK和DEFAULT约束。他们是较老的SQL Server备用约束的一部分,当然也不是没有优点。
自7.0版本之后,MicroSoft指出规则和默认值只是为了向后兼容,而不准备在以后继续支持这个特性。因此对于生成新代码时,应该使用约束。
规则、默认值与约束的本质区别是:约束是一个表的特征,本身没有存在形式,而规则和默认值是表和自身的实际对象,本身存在。约束是在表定义中定义的,而规则和默认值是单独定义,然后"绑定到"表上。
规则和默认值的独立对象特性使得它们可以在重用时不用重新定义。实际上,规则和默认值不限于被绑定到表上,它们也可以绑定到数据类型上。
9.1、规则
规则和CHECK约束非常相似。它们之间的唯一区别是规则每次只能作用于一个列。可以将同一规则分别绑定到一个表中的多个列,但是规则分别作用于每个列,根本不会意识到其他列的存在。像QtyShipped
<= QtyOrdered这样的约束不适用于规则(它引用多个列),而LIKE([0-9][0-9][0-9])这样的定义适用于规则。
定义规则:
下面定义一个规则,这样就可以首先看到区别所在:
CREATE RULE Age18Rule
AS @Age > 18这里比较的是一个变量,不管被检查的列是什么值,这个值将用于替换@Age。因此在这个示例中,规则所绑定的任何列的值都必须大于18。
到目前为止,只是创建了一个规则,但这个规则还没对任何表的任何列起作用,要激活这个规则需要使用一个存储过程:sp_bindrule。
将规则Age18绑定到表person的person_age列:
EXEC sp_bindrule 'Age18Rule','person.person_age';此时,如果我们执行不满足规则的插入操作:
insert into person values ('绑定规则',17)将返回如下报错信息:
消息 513,级别 16,状态 0,第 1 行
列的插入或更新与先前的 CREATE RULE 语句所指定的规则发生冲突。该语句已终止。冲突发生于数据库 'Nx',表 'dbo.person',列 'person_age'。
语句已终止。很明显,规则已经生效。
要特别注意的是,在绑定之前,规则与任何表,任何列都没有关系,因此在绑定的时候,第二个参数要加.指定表名与列名(tablename.column)。
解除绑定规则:
当我们需要在一个列上解除绑定规则的时候,只要执行sp_unbindrule
删除刚才绑定的规则:
EXEC sp_unbindrule 'person.person_age';这时候,执行刚才的插入操作,就不会报错了。
删除规则:
如果希望将规则从数据库中彻底删除,那么可以在表中使用非常熟悉的DROP语法。
DROP RULE <rule name>如删除刚才创建的那条规则:
DROP` `RULE` `Age18Rule9.2、默认值
默认值类似于DEFAULT。实际上默认值-DEFAULT约束的关系与规则-CHECK约束的关系差不多。区别在于它们被追加到表中的方式和对用户自定义数据类型的默认值(是对象,而不是约束)支持。
定义默认值的语法和定义规则类似:
CREATE DEFAULT <default_name>
AS <default value>创建默认值:
因此,假设要为Age定义一个值为0的默认值:
CREATE DEFAULT AgeDefault
AS 0绑定默认值:
同样,如果不绑定到一个对象上,则默认值是不起作用的。要绑定的话,使用存储过程sp_bindefault。
EXEC sp_bindefault 'AgeDefault','person.person_age';要从表中解决默认值的绑定,使用sp_unbindefault:
sp_unbindefault 'person.person_age';删除默认值:
如果要从数据库中彻底删除一个默认值,则可以使用DROP语法,与删除规则相同:
DROP DEFAULT AgeDefault9.3确定哪个表和数据类型使用给定的规则或默认值
如果希望删除或者修改规则或默认值。那么您可以先看看哪些表和数据类型在使用它们。SQL Server还是采用系统存储过程解决这个问题。这个存储过程是sp_depends。其语法如下所示:
EXEC sp_depends <object name>sp_depends提供了依赖于你所查询对象的所有对象列表。
十、系统视图
--CHECK约束,数据来源sys.objects.type='C',
--兼容性视图SYSCONSTRAINTS
select *, ( select c.name from syscolumns c where c.colid = t.parent_column_id and c.id = object_id('Mould')) as 列名
from sys.check_constraints t
where parent_object_id = object_id('Mould');
--默认约束,数据来源sys.objects.type=D,
--兼容性视图SYSCONSTRAINTS
select *, ( select c.name from syscolumns c where c.colid = t.parent_column_id and c.id = object_id('Mould')) as 列名
from sys.default_constraints t
where parent_object_id = object_id('Mould');
--主键或唯一约束,数据来源sys.objects.type PK 和UQ,
--兼容性视图SYSCONSTRAINTS
select * from sys.key_constraints t where parent_object_id = object_id('Mould');
--外键,数据来源sys.object.type=F,
--兼容性视图SYSREFERENCES
select * from sys.foreign_keys t where parent_object_id = object_id('Mould');
--根据表名和列名查询列上的约束
select sysobjects.name, sysobjects.xtype, sysobjects.id
from sysobjects
join sysconstraints on sysobjects.id = sysconstraints.constid
where sysobjects.parent_obj = object_id('Mould') and sysconstraints.colid in ( select colid from syscolumns where id = object_id('Mould') AND name like '%' );