Mongodb学习
聚合
基本语法
MongoDB 的 aggregate 操作使用 MongoDB 的聚合管道(Aggregation Pipeline)来处理数据。聚合管道是由多个阶段(stage)组成的序列,每个阶段执行一种特定的数据处理操作,将处理结果传递给下一个阶段,最终返回处理后的结果。
基本的 aggregate 操作语法如下:
db.collection.aggregate([
{ <stage1> },
{ <stage2> },
...
{ <stageN> }
])
db.sales.aggregate([
{
$group : {
_id : "$item",
totalPrice: { $sum : "$price"},
avgQuantity: { $avg: "$quantity" }
}
}
]);常用聚合阶段(Stages)
MongoDB 的聚合管道中常用的阶段有:
-
$match阶段:用于筛选文档,只传递满足指定条件的文档到下一个阶段。{ $match: { <条件> } } -
$project阶段:格式化输出,用于重新定义文档的结构,包括字段重命名、增加或删除字段等操作。{ $project: { <字段1>: 1, <字段2>: 1, ... } } -
$group阶段:根据指定的键对文档进行分组,并计算每个组的聚合结果。{ $group: { _id: <分组键>, <聚合操作> } } -
$sort阶段:对文档进行排序。{ $sort: { <排序字段>: 1 } } // 1 表示升序,-1 表示降序 -
$limit阶段:限制返回的文档数量。{ $limit: <数量> } -
$skip阶段:跳过指定数量的文档,用于分页。{ $skip: <数量> }
不常用
-
$unwind阶段:将包含数组的字段拆分成多个文档,每个数组元素对应一个文档。{ $unwind: "$arrayField" } -
$lookup阶段:在同一个数据库中,从其他文档中寻找匹配的文档。
实验
一
1)查看系统中已有的数据库;
show databases
show dbs2)创建自定义数据库,名称为:NoSQL;
use NoSQL3)查看当前数据库列表,是否能够查到刚刚创建的数据库?为什么查不到?
查不到4)插入数据,使得这个数据库可以被查到。
db.collection.insertOne({key: value})
db.users.insertOne({name: "John", age: 25})5)统计该数据库的信息;
db.stats()6)删除数据库;
use NoSQL
db.dropDatabase()集合操作:
1)隐式创建集合
use NoSQL
db.collectionName.insertOne({key: value})2)显式创建集合
use NoSQL
db.createCollection("test")3)更改集合的名字
MongoDB 不支持直接更改集合的名称,你需要使用以下步骤来完成重命名操作:
- 将集合的数据复制到一个新的集合中。
- 删除原始集合。
db.collection1.renameCollection("xxx")4)查询当前数据库下所有的集合
show collections5)删除创建的集合
use NoSQL
db.users.drop()二
1、插入文档
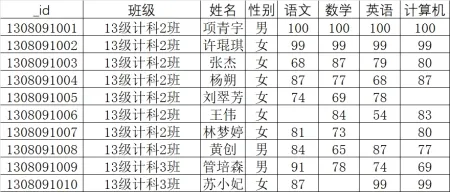
use school;
db.students.insertMany([
{_id: 1308091001, class: '13级计科2班', name: '项青宇', sex: '男', chinese: 100, math: 100, english: 100, computer: 100},
{_id: 1308091002, class: '13级计科2班', name: '许琨琪', sex: '女', chinese: 99, math: 98, english: 97, computer: 99},
{_id: 1308091003, class: '13级计科2班', name: '张杰', sex: '女', chinese: 68, math: 87, english: 88, computer: 77},
{_id: 1308091004, class: '13级计科2班', name: '杨朴', sex: '女', chinese: 87, math: 77, english: 68, computer: 87},
{_id: 1308091005, class: '13级计科2班', name: '刘翠芳', sex: '女', chinese: 74, math: 69, english: 79, computer: 84},
{_id: 1308091006, class: '13级计科2班', name: '王伟', sex: '男', chinese: 82, math: 84, english: 54, computer: 92},
{_id: 1308091007, class: '13级计科2班', name: '林梦婷', sex: '女', chinese: 81, math: 74, english: 87, computer: 94},
{_id: 1308091008, class: '13级计科2班', name: '黄创', sex: '男', chinese: 64, math: 65, english: 64, computer: 85},
{_id: 1308091009, class: '13级计科3班', name: '管浩森', sex: '男', chinese: 91, math: 78, english: 90, computer: 98},
{_id: 1308091010, class: '13级计科3班', name: '苏小妍', sex: '女', chinese: 87, math: 67, english: 99, computer: 95}
]);2、更新操作
将项青宇的语文成绩改为98、数学成绩改为99;
db.students.updateOne(
{name: '项青宇'},
{$set: {chinese: 98, math: 99}}
);3、删除操作
将语文成绩为87的文档删除
db.students.deleteMany({chinese: 87});4、查询操作:
查询语文成绩大于80的文档;
db.students.find({chinese: {$gt: 80}}).pretty();
查询数学成绩小于60的文档;
db.students.find({math: {$lt: 60}}).pretty();
查询英语成绩大于等于75的文档;
db.students.find({english: {$gte: 75}}).pretty();
查询计算机成绩小于等于89的文档;
db.students.find({computer: {$lte: 89}}).pretty();
查询班级为“13级计科2班”且语文成绩大于60的文档;
db.students.find({class: '13级计科2班', chinese: {$gt: 60}}).pretty();
查询班级为“13级计科2班”语文成绩或数学成绩大于80的文档;
db.students.find({class: '13级计科2班', $or: [{chinese: {$gt: 80}}, {math: {$gt: 80}}]}).pretty();
查询班级为“13级计科2班”语文成绩或数学成绩大于80的文档,并跳过前两条数据;
db.students.find({class: '13级计科2班', $or: [{chinese: {$gt: 80}}, {math: {$gt: 80}}]}).skip(2).pretty();
查询班级为“13级计科2班”语文成绩或数学成绩大于80的文档,并仅输出3条数据;
db.students.find({class: '13级计科2班', $or: [{chinese: {$gt: 80}}, {math: {$gt: 80}}]}).limit(3).pretty();
查询班级为“13级计科2班”语文成绩或数学成绩大于80的文档,跳过1条数据,并仅输出2条数据;
db.students.find({class: '13级计科2班', $or: [{chinese: {$gt: 80}}, {math: {$gt: 80}}]}).skip(1).limit(2).pretty();
查询班级为“13级计科2班”语文成绩或数学成绩大于80的文档,并按照语文成绩倒序进行输出。
db.students.find({class: '13级计科2班', $or: [{chinese: {$gt: 80}}, {math: {$gt: 80}}]}).sort({chinese: -1}).pretty();
查询班级为“13级计科2班”语文成绩小于60的文档,并仅输出姓名和语文成绩。
db.students.find({class: '13级计科2班', chinese: {$lt: 60}}, {name: 1, chinese: 1, _id: 0}).pretty();三
索引:
1、创建单键索引
db.grade.createIndex({语文:-1})
2、删除单键索引
db.grade.dropIndex({语文:-1})
3、利用索引进行查询,并查看查询过程
db.grade.find({“语文”: {$lt:60}}).explain()
4、复合索引
db.grade.createIndex({“姓名”:1,“语文”:-1})
利用索引进行查询,并查看查询过程
db.grade.find({“姓名”:‘项青宇’}).explain()
管道:
1、求和:sum
每个班级的人数
db.grade.aggregate([
{ $group: { _id: "$班级", 学生人数: { $sum: 1 } } }
]);2、各班语文的成绩的最大值/最小值
db.grade.aggregate([
{ $group: { _id: "$班级", 语文最高分: { $max: "$语文" } } }
]);
db.grade.aggregate([
{ $group: { _id: "$班级", 语文最低分: { $min: "$语文" } } }
]);3、各班语文的成绩的平均值
db.grade.aggregate([
{ $group: { _id: "$班级", 语文平均分: { $avg: "$语文" } } }
]);4、$project:显示结果的字段进行调整
db.grade.aggregate([
{ $group: { _id: null, 学生人数: { $sum: 1 } } },
{ $project: { "学生人数": 1, _id: 0 } }
]);5、$match:过滤输出条件
输出语文成绩大于80且班级为计科三班的文档,仅输出姓名、语文成绩字段
db.grade.aggregate([
{ $match: { 语文: { $gt: 80 }, 班级: '计科三班' } },
{ $project: { 姓名: 1, 语文: 1, _id: 0 } }
]);6、$sort:结果排序
输出语文成绩大于80且班级为计科三班的文档,并按照语文成绩降序输出,仅输出姓名、语文成绩字段
db.grade.aggregate([
{ $match: { 语文: { $gt: 80 }, 班级: '计科三班' } },
{ $project: { 姓名: 1, 语文: 1, _id: 0 } },
{ $sort: { 语文: -1 } }
]);7、$limit限制显示结果
输出语文成绩大于80的文档前,并按照语文成绩降序输出,仅输出姓名、语文成绩字段,仅输出符合条件的前两个数据
db.grade.aggregate([
{ $match: { 语文: { $gt: 80 } } },
{ $project: { 姓名: 1, 语文: 1, _id: 0 } },
{ $sort: { 语文: -1 } },
{ $limit: 2 }
]);8、$skip略过返回结果的前几项
输出语文成绩大于80的文档前,并按照语文成绩降序输出,仅输出姓名、语文成绩字段,仅输出符合条件的前两个数据,并跳过第一条数据
db.grade.aggregate([
{ $match: { 语文: { $gt: 80 } } },
{ $project: { 姓名: 1, 语文: 1, _id: 0 } },
{ $sort: { 语文: -1 } },
{ $skip: 1 },
{ $limit: 2 }
]);9、输出语文成绩大于70小于等于90的人数
db.grade.aggregate([
{ $match: { 语文: { $gt: 70, $lte: 90 } } },
{ $group: { _id: null, 人数: { $sum: 1 } } },
{ $project: { 人数: 1, _id: 0 } }
]);